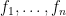
Consider exchangeable random variables 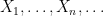
Statement 1. The “variability” of sample mean 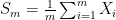

Statement 2. Let the average of functions 
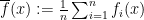

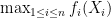
To make these statements precise, one faces the fundamental question of comparing two random variables 

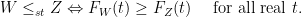
However, this notion really is only a suitable notion when one is concerned with the actual size of the random quantities of interest, while, in our scenario of interest, a more natural order would be that which compares the variability between two random variables (or more precisely, again, the two distributions). It turns out that a very useful notion, used in a variety of fields, is due to Ross (1983): Random variable 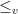
![\displaystyle W \leq_{v} Z \Leftrightarrow \mathbb{E}[f(X)] \leq \mathbb{E}[f(Y)] \ \ \mbox{ for increasing and convex function } f \in \mathcal{F}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+W+%5Cleq_%7Bv%7D+Z+%5CLeftrightarrow+%5Cmathbb%7BE%7D%5Bf%28X%29%5D+%5Cleq+%5Cmathbb%7BE%7D%5Bf%28Y%29%5D+%5C+%5C+%5Cmbox%7B+for+increasing+and+convex+function+%7D+f+%5Cin+%5Cmathcal%7BF%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
where 
One interesting, but perhaps not entirely obvious, fact is that this notion of ordering 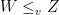
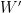
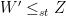
Now with this, we are ready to formalize our previous statements. The first statement is actually due to Arnold and Villasenor (1986):

Note that when you apply this fact to a sequence of iid random variables with finite mean 
The second statement comes up in proving certain optimality result in sharing parallel servers in fork-join queueing systems (J. 2008) and has a similar flavor:
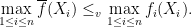
The cleanest way to prove both statements, to the best of my knowledge, is based on the following theorem first proved by Blackwell in 1953 (later strengthened to random elements in separable Banach spaces by Strassen in 1965, hence referred to by some as Strassen’s theorem):
Theorem 1 Let
is that there are two random variables
and
with the same marginals as
almost surely.
For instance, to prove the first statement we consider 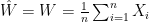
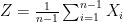
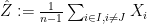

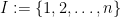
![\displaystyle \mathbb{E} [ \hat{Z} | W ] = \mathbb{E} [ \frac{1}{n} \sum_{J=1}^{n} (\frac{1}{n-1} \sum_{i\in I, i \neq J} X_i ) | W ] = \mathbb{E} [ \frac{1}{n} \sum_{j=1}^{n} X_j | W ] = W.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BE%7D+%5B+%5Chat%7BZ%7D+%7C+W+%5D+%3D+%5Cmathbb%7BE%7D+%5B+%5Cfrac%7B1%7D%7Bn%7D+%5Csum_%7BJ%3D1%7D%5E%7Bn%7D+%28%5Cfrac%7B1%7D%7Bn-1%7D+%5Csum_%7Bi%5Cin+I%2C+i+%5Cneq+J%7D+X_i+%29+%7C+W+%5D+%3D+%5Cmathbb%7BE%7D+%5B+%5Cfrac%7B1%7D%7Bn%7D+%5Csum_%7Bj%3D1%7D%5E%7Bn%7D+X_j+%7C+W+%5D+%3D+W.+&bg=ffffff&fg=000000&s=0&c=20201002)
Similarly to prove the second statement, one can construct