[Admin note: This post comes to us from Zoltan Szabo, of UCL. He is the creator of a new toolbox called Information Theoretical Estimators (ITE).]
I am an applied mathematician working as a research associate at the Gatsby Unit, UCL with Arthur Gretton. My research interest includes dictionary learning problems, kernel methods and information theory. I got acquainted with the estimation of information theoretical quantities while I was working on independent subspace analysis (ISA) and its extensions with Barnabás Póczos who introduced me to this field. ISA is a blind signal separation problem, which can be formulated as the optimization of Shannon’s differential entropy or mutual information objectives. Provided that one can efficiently estimate these quantities, it is possible to solve a wide variety of ISA-type tasks. While I was working on these problems, I gradually realized that the available software packages focus on (i) discrete variables, or (ii) quite specialized quantities and estimation methods. This is what motivated me to write the Information Theoretical Estimators (ITE) toolbox – as a leisure activity.
ITE is a recently released, free and open source, multi-platform, Matlab/Octave toolbox released under GPLv3(>=) license. The goal in ITE is to (i) cover the state-of-the-art nonparametric information theoretical estimators, (ii) in a highly modular, and (iii) user-friendly way. The focus in ITE is on continuous random variables. At the moment the package provide estimators for the following quantities:
- entropy: Shannon entropy, Rényi entropy, Tsallis entropy (Havrda and Charvát entropy), complex entropy,
 -entropy (
-entropy ( -entropy), Sharma-Mittal entropy,
-entropy), Sharma-Mittal entropy,
- mutual information: generalized variance, kernel canonical correlation analysis, kernel generalized variance, Hilbert-Schmidt independence criterion, Shannon mutual information (total correlation, multi-information),
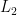 mutual information, Rényi mutual information, Tsallis mutual information, copula-based kernel dependency, multivariate version of Hoeffding’s , Schweizer-Wolff’s
mutual information, Rényi mutual information, Tsallis mutual information, copula-based kernel dependency, multivariate version of Hoeffding’s , Schweizer-Wolff’s  and
and  , complex mutual information, Cauchy-Schwartz quadratic mutual information, Euclidean distance based quadratic mutual information, distance covariance, distance correlation, approximate correntropy independence measure,
, complex mutual information, Cauchy-Schwartz quadratic mutual information, Euclidean distance based quadratic mutual information, distance covariance, distance correlation, approximate correntropy independence measure, 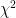 mutual information (Hilbert-Schmidt norm of the normalized cross-covariance operator, squared-loss mutual information, mean square contingency),
mutual information (Hilbert-Schmidt norm of the normalized cross-covariance operator, squared-loss mutual information, mean square contingency),
- divergence: Kullback-Leibler divergence (relative entropy, I directed divergence), divergence, Rényi divergence, Tsallis divergence, Hellinger distance, Bhattacharyya distance, maximum mean discrepancy (kernel distance), J-distance (symmetrised Kullback-Leibler divergence, J divergence), Cauchy-Schwartz divergence, Euclidean distance based divergence, energy distance (specially the Cramer-Von Mises distance), Jensen-Shannon divergence, Jensen-Rényi divergence, K divergence, L divergence, certain f-divergences (Csiszár-Morimoto divergence, Ali-Silvey distance), non-symmetric Bregman distance (Bregman divergence), Jensen-Tsallis divergence, symmetric Bregman distance, Pearson divergence ( distance), Sharma-Mittal divergence,
- association measures including measures of concordance: multivariate extensions of Spearman’s
 (Spearman’s rank correlation coefficient, grade correlation coefficient), correntropy, centered correntropy, correntropy coefficient, correntropy induced metric, centered correntropy induced metric, multivariate extension of Blomqvist’s
(Spearman’s rank correlation coefficient, grade correlation coefficient), correntropy, centered correntropy, correntropy coefficient, correntropy induced metric, centered correntropy induced metric, multivariate extension of Blomqvist’s  (medial correlation coefficient), multivariate conditional version of Spearman’s , lower/upper tail dependence via conditional Spearman’s ,
(medial correlation coefficient), multivariate conditional version of Spearman’s , lower/upper tail dependence via conditional Spearman’s ,
- cross-quantities: cross-entropy,
- kernels on distributions: expected kernel (summation kernel, mean map kernel), Bhattacharyya kernel, probability product kernel, Jensen-Shannon kernel, exponentiated Jensen-Shannon kernel, exponentiated Jensen-Renyi kernel(s), Jensen-Tsallis kernel, exponentiated Jensen-Tsallis kernel(s), and
- +some auxiliary quantities: Bhattacharyya coefficient (Hellinger affinity), alpha-divergence.
The toolbox also offers
- solution methods for ISA and its generalizations – as a prototype application how to formulate and solve an information theoretical optimization problem family in a high-level way.
- several consistency tests (analytical vs estimated value), and
- a further demonstration in image registration – information theoretical similarity measures exhibit exciting outlier-robust characteristics in this domain.
ITE has been accepted for publication in JMLR: Zoltán Szabó. Information Theoretical Estimators Toolbox. Journal of Machine Learning Research 15:217-221, 2014. It was also presented at NIPS-2013: MLOSS workshop.
A few more details: ITE
Feel free to use the toolbox.
Zoltán