
Group 20 – Name Redacted
Brian, Ed, Matt, and Josh
Summary: Our group is creating an interactive and fun way for middle school students to learn the fundamentals of computer science without the need for expensive software and/or hardware.
Description of the tasks:
Binary: In this task, users will be introduced to number systems and learn how to convert between them. Users will be able to make numbers in binary, hexadecimal, octal, or decimal and see the number converted in real time into the other number systems. The program will shows the users how the octal, hexadecimal, and binary numbers are created (i.e. 2^0 * 1 + 2^1 * 1 = 3).
Tutorial: In order to introduce teacher to the basic of the TOY programming interface, they will be guided through a basic tutorial teaching them how to use the features of the system while making a simple program. Users will be guided through the process via on screen text, drawings, and animations that will explain what the onscreen information means, what to do next, and how to interact with the system.
TOY Program: In the TOY programming environment, users (primarily students) will be free to make and experiment with their own programs. Users create programs by placing instruction tags in the correct position and sequence on the whiteboard. The program can then be run, executing instructions in sequence and providing visual feedback to users to help them understand exactly what each instruction does.
Program Initialization: There is also a fourth task that we have created while developing our working prototype. This task is the initialization of the program that requires the users to initialize the webcam and projector space. This task also includes key commands that allow the users to debug their own code, by showing them which lines are grouped together as rows. Part of the idea from the task came from an expansion of the Tutorial feedback, since the tutorial should really begin when the program is first loaded on the teachers laptop.
Choice of the tasks:
We decided not to change our tasks significantly from P4 to P5. Starting with P2, we received feedback from students and an instructor suggesting that binary and visualizing memory were the two hard (and very important) concepts when first learning computer science. There was a general consensus that binary was easier than visualizing memory and coding in TOY. Thus, we really want our tasks to include these two concepts from computer science. Our third task is focused on the teachers who will use our project. This is a logical last task since our user group is both students and teachers. Teachers will need to learn TOY before teaching their students, and thus we need to provide a simple interface to teach them the main concepts in the TOY language. We also cannot assume that every teacher will have an advanced computer science background, so the tutorial has to be simple enough and yet still explain the details of TOY. However, we created a fourth task given the feedback from P4 and the information gained while building the prototype. We are going to provide a simple interface for teachers to learn how to initialize our system. This is very simple, and just requires the teacher to push “i” to map the webcam space to the projector space, but is still very important nonetheless. It will also require telling the teacher how to put tags on the board to switch between TOY Programming, the tutorial, and binary.
Revised Interface Design:
The big push of our work this week was to try and fit the design aspiration of the projects to the realities of the technologies. At the core of our project is a fundamental platform we created that allows developers to write applications on top of it. Before talking about the specific applications that we implemented, I want to touch on the design choices that we had to make for the platform itself. These are design choices that we couldn’t have conceived of while doing the paper prototype because the reality of the technology did not exist. Our fundamental platform interface is this: Users boot the program on a computer attached to a monitor. Two visualizations are rendered on the screen. The first is the projector space. This is where applications can write. The second is the monitor space. This is where the camera image is displayed. The camera is then pointed at the projector and the “i” key is pressed. This starts our “initialization mode,” where we align the projector coordinates with the camera coordinates and calculate the appropriate translation. After the system has been initialized, you can then press the “u” key to display debug information on the projector. When tags are placed on the screen, their corners are highlighted by the projector showing that it is properly aligned. Also, when tags are organized into rows, those rows are highlighted to show that they tags are semantically connected. The debugging information is a UI that we expose to Applications developers so they can see visually, how the framework is interpreting the images on the screen.
Moving on to some of our applications, the first application that we implemented is assembly. We stuck with the same general layout as our paper prototype. We had iterated through where we were going to place the “code,” “output,” and “registers” sections previous to the final paper prototype. Given the feedback that we received during prototype testing, we felt that this final layout (code on the left, registers and output on the right) was the most effective. We did play around with various output types. This is again something that didn’t come up as much during the paper prototyping phase. Now output needs to scroll. We also dealt with the clearing of the output field when programs were re-launched because that was something that our testers had found confusing.
Our second application that we implemented with our number base conversion application (We call it “Binary”). This is where the user can see how different number representations might display the same numerical value. Our paper prototype was very free-form and allowed for users to place the tags anywhere on the board. This lead to confusion, where users would either place too many tags on the board or place tags in the same row when they did not mean to. We therefore altered our design so it was more constructive. We created a grid that the users could populate with values. This suggests to them that they need to separate the rows spatially and also helps them to understand that they should only fill in a single field at a time.
Moving forward, we have a couple of interesting features we have yet to implement. I think the biggest place where UI design will have to play a role is error messaging. With the complexity of our Assembly application, we saw that users are already prone to creating erroneous and nonsensical programs. This is not a problem with our application. Some of the greatest “teachable moments” in computer science come not out of writing correct programs but realizing why a given program is incorrect. We therefore want to make sure that the user gets the most informative UI possible when an error is received. This will include syntax highlighting and visual feedback. We have created a few sketches of possible designs in the slideshow below.
Overview and Discussion of Prototype:
i) Implemented Functionality
Our project can read in the AR Tags with a webcam, and apply the correct homography translations to map the webcam space to the projector space. This allows us to circle tags with the projector that are on the wall. We used this functionality to create our debugging API which allowed us to get the extensive backend code fully operating. Our debugging API also gave us greater insight into the limitations of AR Tags. Namely, AR Tags on a screen must be unique. There are 1024 different possible AR Tag combinations, and so we are in the process of creating multiple tags for register names, TOY labels, and integer literals. We also have a TOY to Java compiler and interpreter that allows any sequence of the commands to be read and executed. The debugging API that we have been using for development will evolve into a debugging API for the students using the program, where incorrect syntax will be highlighted and errors shown on the output side. The big hurdles when creating the backend and preliminary front end interfaces were getting familiar with Processing, determining the limitations of Processing and AR Tags, and creating a suitable abstraction that will allow for easy proliferation of tasks. We have created a very simple abstraction that would allow programmers to easily create new applications, as well as allow us to create new applications. No matter what the frontend application, we have created an interface that the backend can interact with, so that a new application would require no new backend programming. Overall, both the frontend and backend code together are more than 1300 lines of code, almost all of which we wrote (tutorials borrowed from listed below). We wanted to talk extensively about the backend functionality because it required a lot of work and hours, but it enabled us to create an interface that will make finishing the project much simpler. Although the frontend programming is not completely done (and most of the “wow” factor comes from the frontend features), the backend is certainly the hardest part of the assignment and it is nearly complete for the project. The TOY Program is also nearly complete, and the binary program should not take much more time given the interfaces and abstractions that we created. The Tutorial is just an extension of the TOY Program.
ii) Left Out Functionality
We decided to leave out the error messages that the TOY Program generates for a few reasons. Firstly, all of the code is there to implement the feature, but we are currently focusing on our debugging and thus we have made the output images projected help us rather than a potential future user. However, the red boxes seen in the images in the next section are essentially the same as the error messages that users will see in the final product, but for now we were more concerned with debugging the back end and extensive tag libraries that we had to write. In a similar fashion, we left out some of the messages that will appear during the tutorial, but the messages will appear in the output section of the TOY Program, which is already set up to print the desired tutorial messages. In the meantime, however, we wanted to use this section for our own debugging purposes. Now that we have basically finished the backend, we can start specializing these parts of the code to focus on the user. The functionality that we decided to leave out is very easy to add, but for the time it is more important to create a debugging framework.
iii) Wizard-of-Oz Techniques
There are no wizard-of-oz techniques for the TOY Program. However, the output for the binary program is hard coded in for now, while we further develop that individual program. We are also going to accept the advice of our paper prototype testers and put more information about how we calculate the binary output. Also, at the time we only have one tag corresponding to each command and number. By the final prototype we are going to have multiple tags for each command and number so that the programs can be more complete. We only have one tag corresponding to each number since it took so much coding on the backend and the debugging API to be completed before realizing that limitation of the AR Tag library. We decided to have the output for binary hard coded in for now since we wanted to really finalize the backend of the application with a layer of abstraction that would make coding the rest of the binary program very easy. Thus, we decided to focus much more on getting the backend complete than on the frontend applications. This makes sense, since the frontend could not run without the backend basically completed.
v) Documented Code
For the AR tag detection, we are using the NyARToolkit, a Java implementation of the ARTooKit Library, available at http://nyatla.jp/nyartoolkit/wp/. For calculating homography, we are using the homography library created by Anis Zaman Keith O’Hara, available at https://code.google.com/p/the-imp/source/browse/src/PCLT/src/edu/bard/drab/PCLT/Homography.java?r=7a9657a65e976ac38b748b35fa7b36806326011d. We used a Processing and ARToolKit tutorial to get started, but only small elements of this tutorial remain in our current code. This tutorial is available at http://www.magicandlove.com/blog/research/simple-artoolkit-library-for-processing/.
Documentation

Testing setup.
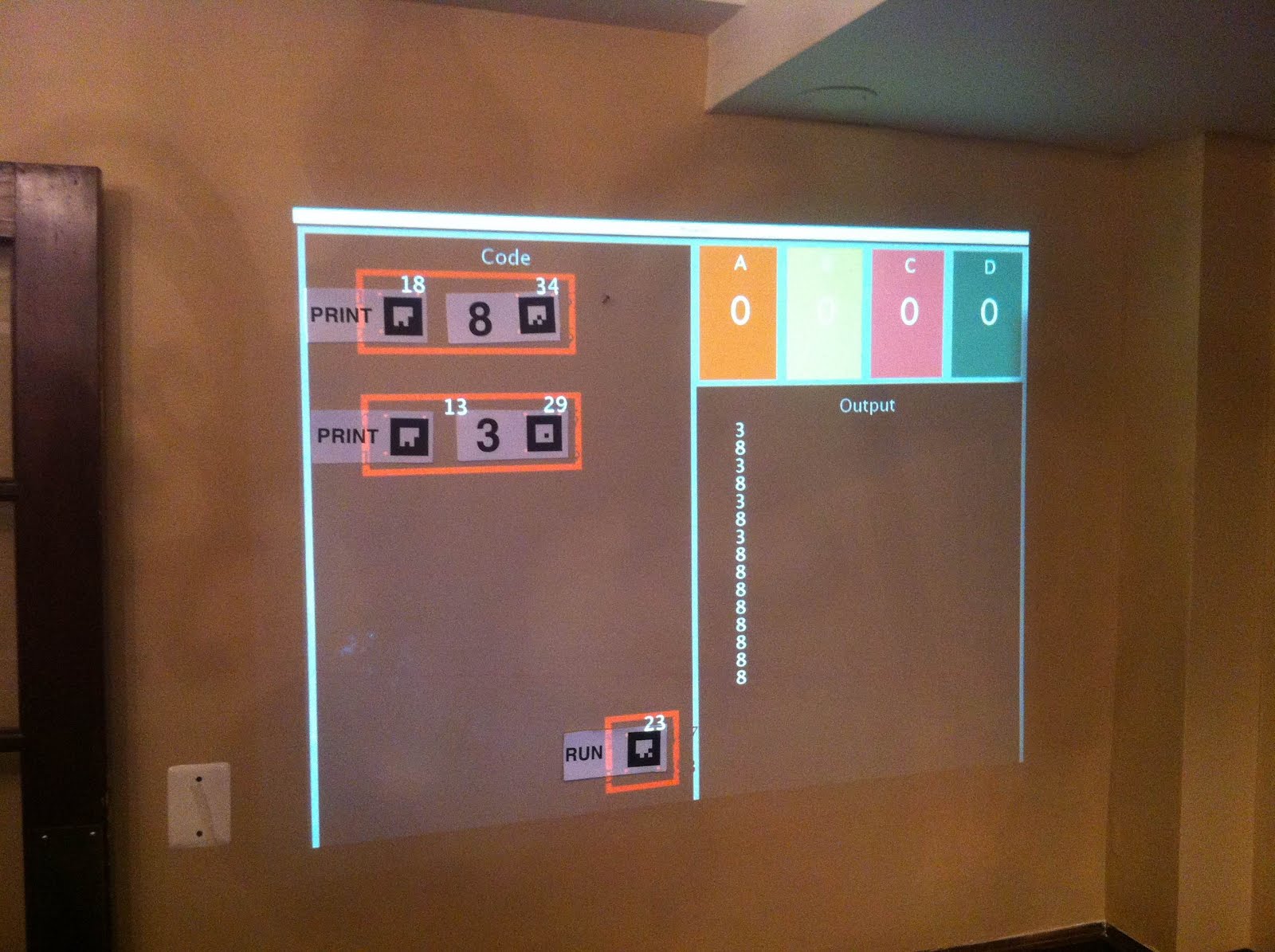
Toy Program. The red boxes are for debugging, showing that the homography is working and the tags are correctly identified. The output correctly shows the results of the program (which has been run multiple times).
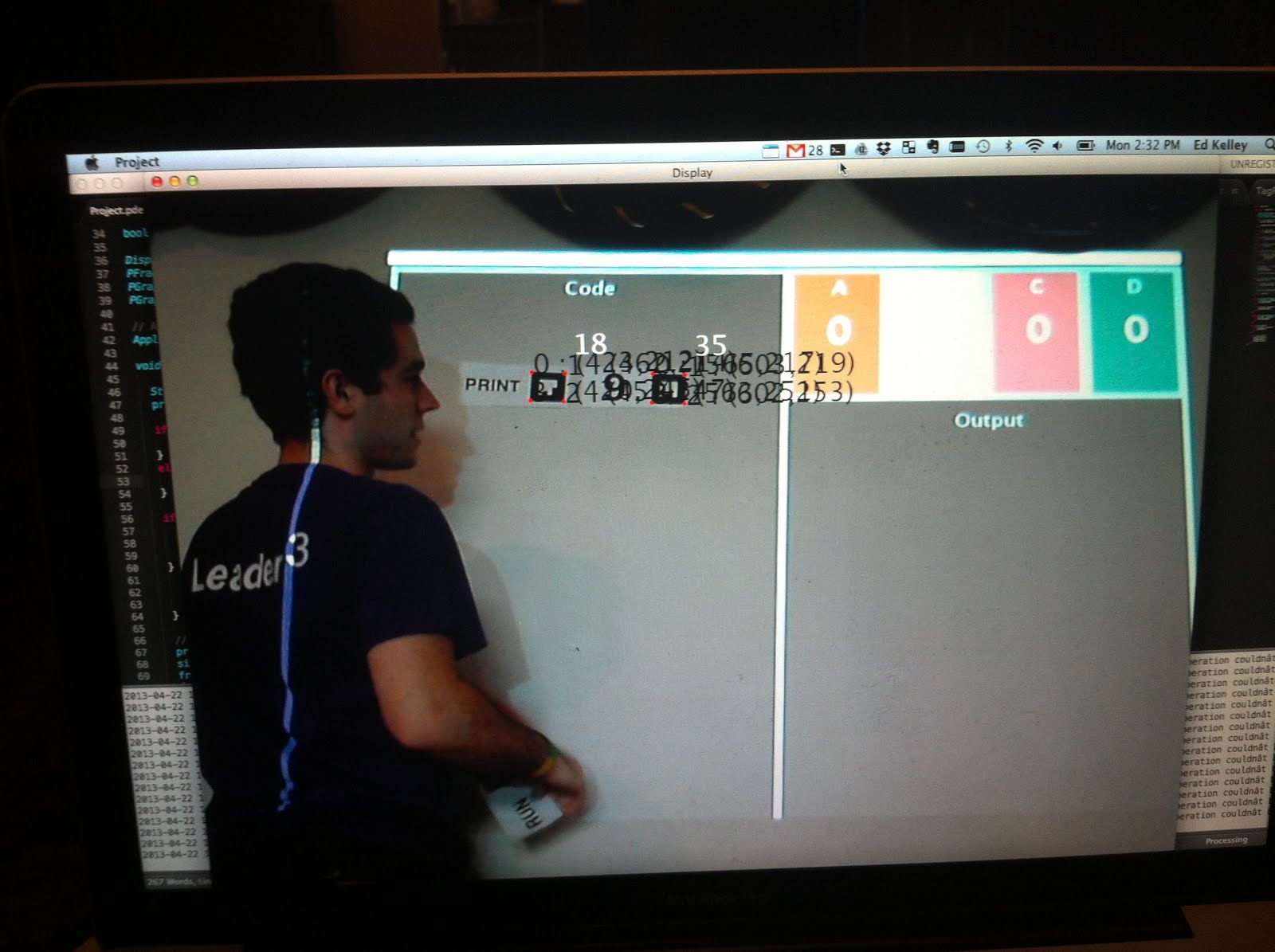
Monitor display. Shows tag debugging information and camera view.

Testing system on a projector screen.

Example of the Binary program. Currently hard-coded values used. However, building the application in our framework will be a relatively simple task.