Update (4/3/2014): I believe I have solved the conjecture, and proven it to be correct. I will make a preprint available shortly(see link below). The original blog post remains available below. — Tom
Preprint available here: “An extremal inequality for long Markov chains“.
I have an extremal conjecture that I have been working on intermittently with some colleagues (including Jiantao Jiao, Tsachy Weissman, Chandra Nair, and Kartik Venkat). Despite our efforts, we have not been able to prove it. Hence, I thought I would experiment with online collaboration by offering it to the broader IT community.
In order to make things interesting, we are offering a $1000 prize for the first correct proof or counterexample! Feel free to post your thoughts in the public comments. You can also email me if you have questions or want to bounce some ideas off me.
Although I have no way of enforcing them, please abide by the following ground rules:
- If you decide to work on this conjecture, please send me an email to let me know that you are doing so. As part of this experiment with online collaboration, I want to gauge how many people become involved at various degrees.
- If you solve the conjecture or make significant progress, please keep me informed.
- If you repost this conjecture, or publish any results, please cite this blog post appropriately.
One final disclaimer: this post is meant to be a brief introduction to the conjecture, with a few partial results to get the conversation started; it is not an exhaustive account of the approaches we have tried.
1. The Conjecture
Conjecture 1. Suppose
are jointly Gaussian, each with unit variance and correlation
. Then, for any
satisfying
, the following inequality holds:
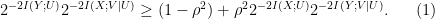
2. Partial Results
There are several partial results which suggest the validity of Conjecture 1. Moreover, numerical experiments have not produced a counterexample.
Conjecture 1 extends the following well-known consequence of the conditional entropy power inequality to include long Markov chains.
Lemma 1 (Oohama, 1997). Suppose
satisfying
, the following inequality holds:
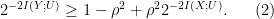
Proof: Consider any 
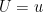

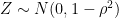

From here, the lemma easily follows.

Lemma 1 can be applied to prove the following special case of Conjecture 1. This result subsumes most of the special cases I can think of analyzing analytically.
Proposition 1. Suppose

Proof: Without loss of generality, we can assume that ![{\rho_u = E[XU]}](https://s0.wp.com/latex.php?latex=%7B%5Crho_u+%3D+E%5BXU%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
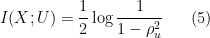
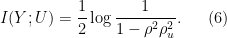
Let 
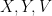
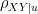
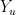
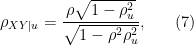
which does not depend on the particular value of 

For every 

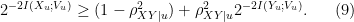
The desired inequality (8) follows by convexity of
![\displaystyle \log\left[(1-\rho_{XY|u}^2)+ \rho_{XY|u}^2 2^{-2z}\right] \ \ \ \ \ (10)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Clog%5Cleft%5B%281-%5Crho_%7BXY%7Cu%7D%5E2%29%2B+%5Crho_%7BXY%7Cu%7D%5E2+2%5E%7B-2z%7D%5Cright%5D+%5C+%5C+%5C+%5C+%5C+%2810%29&bg=ffffff&fg=000000&s=0&c=20201002)
as a function of 
3. Equivalent Forms
There are many equivalent forms of Conjecture 1. For example, (1) can be replaced by the symmetric inequality
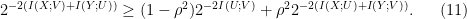
Alternatively, we can consider dual forms of Conjecture 1. For instance, one such form is stated as follows:
Conjecture 1′. Suppose
, the infimum of
taken over all
are jointly Gaussian.
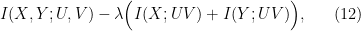
This example counters this conjecture.
U=2*U1 ;
X1=2*(U1+U2+ …+U20) ;
X=(X1-mean(X1))/std(X1);
Y=0.1*X+W1;
V=0.9*Y+0.1*W2;
where Ui(0,1) is uniform, (i=1,2, … ,20), W1~N(0,0.99), and W2~N(0,1).
I got the following numerical results for this setting using 10^7 samples.
H(U,V)= 81.4570,
H(Y,U)= 11.8206,
H(X,V)= 69.5232,
H(X,U)= 11.9757,
H(Y,V)= 7.4803,
Just curious, what would the implications be if this conjecture is true?
Nice question, I would like to know too!
Has this conjecture been solved or have there been any further insights? Just curious as I’ve been trying to tackle this problem for a while.
No, it is not solved yet. However, I recently gave a talk on the conjecture at the 2014 International Zurich Seminar on Communications. The paper should be available on my website shortly.
[I have received several emails inquiring about the status of the conjecture, so I have added a comment at the top of the post to advertise the status. I will update it if the status changes.]
Oh, what a coincidence, I happen to study there. Thanks for the quick reply!
Does “UV” in Conjecture 1′ stands for the product of U and V?
No, it denotes the pair of random variables (U,V).
In the other puzzle (http://arxiv.org/pdf/1302.2512v2.pdf), Isn’t 1 − H(α) channel capacity? and hence mutual information between f(x) and y is less than the capacity for all functions?
$I(f(x),y) > max I(x,y)=1-H(alpha)$ seems to be impossible.
You have to be careful here. The problem you are talking about considers mutual information of the form:
I( b(X^n) ; Y^n ), where (X^n,Y^n) are n i.i.d. pairs of correlated Bernoulli(1/2) random variables. In this case, the data processing inequality looking at the channel X^n –> Y^n (which is what you are driving at with your channel capacity statement) simply gives:
I( b(X^n) ; Y^n ) <= n*( 1-H(\alpha) ),
which is off by a factor of n. Clearly this is no good, since we can trivially upper bound:
I( b(X^n) ; Y^n ) <= 1.
Appealing to a so-called 'strong data processing' inequality improves things, but still only gives:
I( b(X^n) ; Y^n ) <= (1-2\alpha)^2,
which is still weaker than the conjecture.
Hello dear friends,
I saw this post some months ago, but because I was busy, I did not say anything about it. If it is not solved yet, so I will be so delighted to work on this Conjecture.
The conjecture is not solved yet. That’s what Tom Courtade told me today. Good luck!
What do you mean by “satisfying U – X – Y – V”. Is this a typo that’s supposed to say something like “satisfying U – X = Y – V”, or is there some other notation that I’m not familiar with?
The notation U-X-Y-V means that U,X,Y,V form a Markov chain, in that order. In other words, we can factor the joint distribution as p(x,y,u,v) = p(u|x)p(v|y)p(x,y).
I read your post by chance. I will have a try.
I think you are undervaluing a good counter example!
Perhaps. The prizes reflect our feeling that a counterexample would require one appropriately normalized unit of effort, while a proof would require four units. Hence, dollars earned per unit effort should be constant regardless of outcome 🙂
I want to think on this