The first issue of Information and Inference has just appeared:
http://imaiai.oxfordjournals.org/content/current
It includes the following editorial:
In recent years, a great deal of energy and talent have been devoted to new research problems arising from our era of abundant and varied data/information. These efforts have combined advanced methods drawn from across the spectrum of established academic disciplines: discrete and applied mathematics, computer science, theoretical statistics, physics, engineering, biology and even finance. This new journal is designed to serve as a meeting place for ideas connecting the theory and application of information and inference from across these disciplines.
While the frontiers of research involving information and inference are dynamic, we are currently planning to publish in information theory, statistical inference, network analysis, numerical analysis, learning theory, applied and computational harmonic analysis, probability, combinatorics, signal and image processing, and high-dimensional geometry; we also encourage papers not fitting the above description, but which expose novel problems, innovative data types, surprising connections between disciplines and alternative approaches to inference. This first issue exemplifies this topical diversity of the subject matter, linked by the use of sophisticated mathematical modelling, techniques of analysis, and focus on timely applications.
To enhance the impact of each manuscript, authors are encouraged to provide software to illus- trate their algorithm and where possible replicate the experiments presented in their manuscripts. Manuscripts with accompanying software are marked as “reproducible” and have the software linked on the journal website under supplementary material. It is with pleasure that we welcome the scien- tific community to this new publication venue.
Robert Calderbank David L. Donoho John Shawe-Taylor Jared Tanner
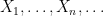 . A couple of facts seem quite intuitive:
. A couple of facts seem quite intuitive: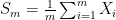 decreases with
decreases with  .
. be defined as
be defined as 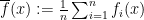 . Then
. Then  is less “variable” than
is less “variable” than 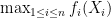 .
. and
and  (or more precisely comparing two distributions). One common way we think of ordering random variables is the notion of stochastic dominance:
(or more precisely comparing two distributions). One common way we think of ordering random variables is the notion of stochastic dominance: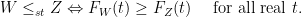
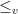 ) when every risk-averse decision maker will choose
) when every risk-averse decision maker will choose ![\displaystyle W \leq_{v} Z \Leftrightarrow \mathbb{E}[f(X)] \leq \mathbb{E}[f(Y)] \ \ \mbox{ for increasing and convex function } f \in \mathcal{F}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+W+%5Cleq_%7Bv%7D+Z+%5CLeftrightarrow+%5Cmathbb%7BE%7D%5Bf%28X%29%5D+%5Cleq+%5Cmathbb%7BE%7D%5Bf%28Y%29%5D+%5C+%5C+%5Cmbox%7B+for+increasing+and+convex+function+%7D+f+%5Cin+%5Cmathcal%7BF%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
 is the set of functions for which the above expectations exist.
is the set of functions for which the above expectations exist.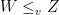 is equivalent to saying that there is a sequence of mean preserving spreads that in the limit transforms the distribution of
is equivalent to saying that there is a sequence of mean preserving spreads that in the limit transforms the distribution of 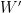 with finite mean such that
with finite mean such that 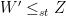 ! Also, using results by Hardy, Littlewood and Polya (1929), the stochastic variability order introduced above can be shown to be equivalent to Lorenz (1905) ordering used in economics to measure income equality.
! Also, using results by Hardy, Littlewood and Polya (1929), the stochastic variability order introduced above can be shown to be equivalent to Lorenz (1905) ordering used in economics to measure income equality.
 , it strengthens the strong law of large number in that it ensures that the almost sure convergence of the sample mean to the mean value
, it strengthens the strong law of large number in that it ensures that the almost sure convergence of the sample mean to the mean value 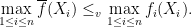
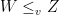 is that there are two random variables
is that there are two random variables 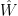 and
and 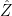 with the same marginals as
with the same marginals as ![{\mathbb{E}[\hat{Z} |\hat{W}] \geq \hat{W}}](https://s0.wp.com/latex.php?latex=%7B%5Cmathbb%7BE%7D%5B%5Chat%7BZ%7D+%7C%5Chat%7BW%7D%5D+%5Cgeq+%5Chat%7BW%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) almost surely.
almost surely. 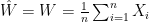 and
and 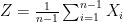 . All that is necessary now is to note that
. All that is necessary now is to note that 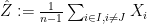 ,
,  is an independent uniform rv on the set
is an independent uniform rv on the set 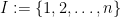 , has the same distribution as random variable
, has the same distribution as random variable ![\displaystyle \mathbb{E} [ \hat{Z} | W ] = \mathbb{E} [ \frac{1}{n} \sum_{J=1}^{n} (\frac{1}{n-1} \sum_{i\in I, i \neq J} X_i ) | W ] = \mathbb{E} [ \frac{1}{n} \sum_{j=1}^{n} X_j | W ] = W.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BE%7D+%5B+%5Chat%7BZ%7D+%7C+W+%5D+%3D+%5Cmathbb%7BE%7D+%5B+%5Cfrac%7B1%7D%7Bn%7D+%5Csum_%7BJ%3D1%7D%5E%7Bn%7D+%28%5Cfrac%7B1%7D%7Bn-1%7D+%5Csum_%7Bi%5Cin+I%2C+i+%5Cneq+J%7D+X_i+%29+%7C+W+%5D+%3D+%5Cmathbb%7BE%7D+%5B+%5Cfrac%7B1%7D%7Bn%7D+%5Csum_%7Bj%3D1%7D%5E%7Bn%7D+X_j+%7C+W+%5D+%3D+W.+&bg=ffffff&fg=000000&s=0&c=20201002)
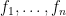 .
.