Education Background: I recently graduated from Rutgers University with my Master’s in Information Science with a concentration in archives and preservation. I also did my undergraduate degree at Rutgers, where I studied history and American studies.
Previous Experience: After graduating college, I interned at the Zimmerli Art Museum, where I cataloged and processed the newly acquisitioned Jersey City Museum collection. This experience is what ultimately inspired me to go to library school and enter this field. Then, while in graduate school, I was a Library of Congress Junior Fellow, where I had the chance to create two online exhibitions for the American Archive of Public Broadcasting (AAPB). In addition to learning a lot about public broadcasting and about the PBS NewsHour, working on these projects reified my interest in curation and public services.
Most recently, during my last two semesters as a graduate student, I worked at the Institute of Jazz Studies at the Rutgers-Newark Library, where I created descriptive metadata and authority records for audio files, completed online reference requests, digitized materials for research access and for long-term preservation, and performed a number of other tasks necessary to the day-to-day functioning of an archive.
Why I like Archives/Professional Interests: While I was initially drawn to the field because of my love of history and of the bizarre objects that inevitably end up in special collections, my continued interest in archives stems from its power as an institution to influence our understanding of the past, present, and future. I hope that by entering this field I can help effect positive social change by pushing for a more inclusive perspective of history.
Other interests: I love knitting and experimenting with other fiber arts techniques. I learned how to knit when I was in elementary school and picked it up again in college, where I made a lot of lumpy hats. Then, because of COVID-19 and the 2020 lockdown, I had a lot more time to practice and finally graduated to knitting sweaters.
Looking forward to working on the following project(s) while at Princeton: I’m most excited to start working on the redescription projects with the Inclusive Description Working Group! I’m also looking forward to working with patrons and getting more experience providing in-person reference services.
This Spring, Special Collections participated as a host institution in a PACSCL (Philadelphia Area Consortium of Special Collections Libraries)-sponsored semester-long, pilot DEI internship program to provide an undergraduate student from an underrepresented community/ies exposure to and experience working in a special collections library. The following was authored by Princeton student August Roberts ’25 about her experience.
August Roberts ’25
When I was interviewing for the PACSCL internship for the Princeton University Library, I was asked, “What part of special collections are you most interested in learning more about?” As I scoured my brain for an answer, I quickly realized that I knew very little about the specific work that goes into special collections. All I knew is that I had a passion for preserving knowledge in all its forms matched only by a passion for making that knowledge accessible to as many people as possible.
As a member of the LGBTQ+ community, I have grown increasingly passionate about information accessibility and preservation. Queer stories have frequently been censored or destroyed, just have the stories of many other marginalized communities. While working with the various departments within Princeton’s Special Collections, I have had the opportunity to listen to oral histories in the Princeton LGBTQIA Oral History Project, work with texts important to queer history, and learn more about how cataloging can influence the ease at which LGBTQ people and people from other marginalized groups are able to access materials relating to their personal communities.
In addition to connecting with my identity-based community through this internship, I have also been able to directly connect with the community at Princeton. Before this internship, I knew very little about any of the libraries on campus. However, as I explored the different collections, I began to understand the depth of what I could access and study as a Princeton student. Additionally, I learned more about how archives and libraries function in general to assist researchers and the public, knowledge I will continually use throughout my academic career and afterwards.
I am very grateful for all of the wonderful people who I worked with over the course of this internship. Before I began, I was nervous that I didn’t know enough to do what might be expected of me. However, this feeling quickly subsided as I met more of the people who work in Princeton’s Special Collections. Each one patiently taught me about their specific field of work and discussed some of the complex issues surrounding Special Collections, introducing me to the importance of libraries and the challenges which the people working in them are tasked with unraveling. I look forward to continuing my exploration of special collections and libraries throughout my lifetime, both on campus and beyond!
The Mudd Manuscript Library, a unit of Princeton University Library’s Department of Special Collections, offers the John Foster and Janet Avery Dulles Archival Fellowship for one graduate student (or recent graduate) each year. This fellowship provides a summer of work experience for those interested in pursuing an archival career. For more information about the Mudd Manuscript Library visit: https://library.princeton.edu/special-collections/mudd.
The 2022 Fellow will gain experience in both technical and public services, working under the guidance of archivists from both teams. Projects for 2022 may include: a research project on implementing reparative description, processing/reprocessing work on both analog and digital collections, and participation in the reference rotation. Previous Fellows and their work can be found on our website.
The Mudd Library stewards the Princeton University Archives and a collection of 20th-century public policy papers. The more than 35,000 linear feet of archival and manuscript material are widely used by local, national, and international researchers. More than 2,000 visitors use Mudd Library’s reading room each year, and its staff field some 3,000 electronic, mail, and telephone inquiries annually. A progressive processing program, the use of new technologies, and an emphasis on access and public service have ensured that Mudd Library’s collections are ever more accessible.
The 10- to 12-week fellowship, which may be started as early as May, provides a stipend of $1000 per week. In addition, costs related to attending a professionally-related, national conference will be covered. Details on travel and in-person attendance will depend on University guidance regarding current Covid-19 protocols.
Requirements: Successful completion of at least 12 graduate semester hours (or the equivalent) applied toward an advanced degree in archives, library or information management, American history, American studies, or museum studies. Applicants within one year of obtaining their graduate degree are also eligible to apply. Demonstrated interest in the archival profession; good organizational and communication skills; and a willingness and commitment to learn new tools/applications. Experience with processing and reference, as well as familiarity with ArchivesSpace, preferred. The Library highly encourages applicants who identify as a member of a group (or groups) underrepresented in the library and archives field. These include—but are not limited to—people of Hispanic or Latinx, Black or African-American, Asian, Middle Eastern, Native Hawaiian or Pacific Islander, First Nations, American Indian, or Alaskan Native descent as well as people with disabilities, first generation college graduates, and/or those who identify as LGBTQIA+.
To apply: Applicants should submit a cover letter, resume, and two letters of recommendation to: mfellow@princeton.edu . Any questions about the application process or position can be sent to the same email. Applications must be received by Monday, March 7, 2022 at 11pm. Interviews will be conducted (via phone and/or video) with selected candidates and the successful candidate will be notified by April 8, 2022.
Please note: University housing will not be available to the successful candidate. Interested applicants should consider their housing options carefully and may wish to consult the Tiger ReTail, the online campus bulletin board or the Princeton University Off-campus Housing website for more information on this topic.
Princeton University Library’s Department of Special Collections is excited to offer the Special Collections Summer Fellowship hosted at Firestone Library (previously the Archival Residency for Manuscripts Division Collections) again for 2022.
Princeton University Library’s Department of Special Collections is excited to offer the Special Collections Summer Fellowship hosted at Firestone Library (previously the Archival Residency for Manuscripts Division Collections) again this year.
The fellowship provides a summer of paid work experience for a current or recent graduate student interested in pursuing a career in Special Collections libraries or archives.
Fellowship Description: The 2022 Fellow will gain experience in the fields of technical services, public services, and curatorial. Projects for 2022 may include: learning and implementing reparative description; processing/reprocessing of manuscript collections (including hybrid collections with born-digital and audiovisual materials); participation in the reference rotation and answering reference questions in person and remotely; working alongside curatorial staff to learn and implement contemporary collecting and stewardship practices, and conducting research on areas of scholarly inquiry and supporting curatorial projects as an integral part of an acquisitions team.
This ten- to twelve-week residency program, which can begin as early as May, provides a weekly stipend of $1000 (subject to state/local/federal taxes). In addition, expenses for attending one North American-based conference of the fellow’s choosing (travel, registration fees, and hotel) will be covered by Princeton University Library.
Requirements:
Must be a current graduate student or recent graduate (within one year of graduation) of an advanced degree program in archive or library/information management, museum studies and public history, literature, American studies, history, and/or other humanistic discipline.
Must have past experience working in the archival and/or special collections profession (including positions held as part of volunteer programs, internships, work-study programs, contract/adjunct work, other fellowships, etc.)
Good organization and communication skills.
Time management and project management skills (ability to manage multiple projects).
Foreign language skills (particularly Spanish-language reading skills) are preferred, but not essential.
To apply: Submit a cover letter, resume, and two letters of recommendation addressed to the search committee at esarconi@princeton.edu with the subject line “[Applicant Last Name] 2022 Archival Fellowship.” Applications must be received by Tuesday, March 1st, 2022. Zoom interviews will be conducted with the top candidates at the end of March, and the successful candidate will be notified by April 15th.
Please note: University housing will not be available to the successful candidate. Interested applicants should consider their housing options carefully and may wish to consult the online campus bulletin board for more information on this topic.
Image above shows photos of various authors represented throughout the Princeton Latin American collections, including Carlos Fuentes, Octavio Paz, José Bianco, Elena Garro, Idea Vilariño,Ricardo Piglia, Arcadio Díaz Quiñones, Reinaldo Arenas, Reina María Rodríguez, Pedro Juan Gutiérrez, Juan Gelman and José Emilio Pacheco.
There are numerous ongoing initiatives and conversations in the archival profession revolving around issues of racial and social justice, and language justice is one of the key components of both. The term “language justice” as defined in the Language Justice Toolkit, “… is about building and sustaining multilingual spaces in our organizations and social movements so that everyone’s voice can be heard both as an individual and as part of a diversity of communities and cultures. Valuing language justice means recognizing the social and political dimensions of language and language access, while working to dismantle language barriers, equalize power dynamics, and build strong communities for social and racial justice.”[1]
As a result, what language is used in our finding aids to describe collections is inherently tied to movements of decolonization, as well as racial and social justice. Princeton University has extensive holdings of Latin American archives, and Spanish is the predominant language of these materials, yet the description in the majority of the legacy finding aids is written in English. It is probably safe to assume that a considerable number of the likely users of these collections would be native Spanish speakers, and some might not even read English. Therefore, why impede the accessibility and navigation of the contents in finding aids by imposing English as the default language? In a 2010 study investigating the usages and expectations of multilingual resources in Chinese digital libraries conducted by Dan Wu, Nanhui Gu, and Daqing He, users had considerably more difficulties searching for information created in a language that they do not understand. Many users in this situation reported having to rely on online translation tools, but in general, were not satisfied with the accuracy of the translations.[2]
By creating finding aids in Spanish, Spanish-speaking researchers can more easily access and navigate archival collections without having to rely exclusively on translation tools. As part of applying language justice concepts to our descriptive practices, patrons should not have to be able to read or find alternative methods of understanding the dominant English language in order to engage with the collections found in our institutions, especially those that may be of direct relevance to themselves and their communities. As Dorothy Berry writes, “Our descriptive systems are often the first interaction patrons have with our institutions, and when the language and systems feel alienating, patrons will take what they need and leave the rest… The question of who will come visit is rarely asked of the house we have built and whether or not our door has ever been truly open in the first place.”[3]
The growing interest in inclusive description efforts with the intent of being more respectful of the communities and the people that are impacted by our descriptive work should also be directed towards the language we use in our finding aids. It is not only the right thing to do, but will also lead to building trust and engagement with communities that we are supposedly trying to serve. As Xaviera Flores and Elizabeth Dunham note in their article on bilingual finding aids, “Spanish-language finding aids have proven to be valuable tools for building community relationships and further developing the Chicano/a Research Collection. The Collection’s curator and curator emerita both report encountering members of the Mexican American community who feel that Spanish finding aids show an appreciation and respect of the language and culture that is often lacking in their dealings with Anglo society.”[4]
At Princeton University Library, my predecessor, Elvia Arroyo-Ramírez, began creating some bilingual finding aids, wherein collection- and series- level descriptions were written in English, but folder titles and more detailed file-level scope and content notes were written in Spanish, as seen in the finding aid for the Idea Vilariño Papers.
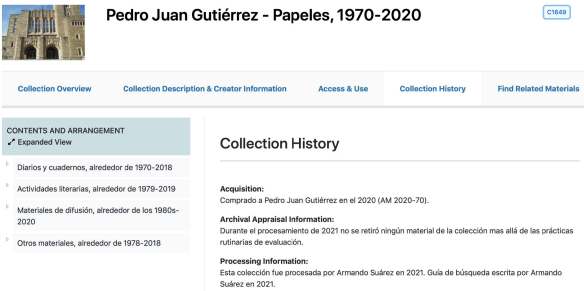
Subsequently, a few months after my hiring, the Inclusive Description Working Group [5] was formed in May 2019, composed of a group of archivists committed to tackling the complex issue of cultural sensitivity in archival description, and to critically rethinking our role as archivists in order to create description that is respectful to the individuals and communities who create, use, and are represented in the archival collections we manage. One issue that the group began to discuss is which language to use when writing finding aids for archival collections in which most of the materials are not in English. As a result of these discussions, we are now writing finding aids in Spanish for predominantly Spanish-language collections, as seen in the screenshots below for the collections of Jorge Díaz and Pedro Juan Gutiérrez respectively.
Finding aid for the Jorge Díaz Papers, 2021. Princeton University Library.Finding aid for the Pedro Juan Gutiérrez Papers, 2021. Princeton University Library.
Language is a carrier of culture and communication[6] and forms an integral part of one’s identity. Reading and speaking in one’s native language provides a sense of connection to one’s culture, community, and self. Therefore, as we move forward at Princeton University Library, we will continue to work to ensure that newly-processed, predominantly Spanish-language collections have corresponding finding aids written in Spanish. With our recent migration to ArchivesSpace, we also launched a new finding aid discovery site. As we continue to make improvements to these platforms, we will look for ways to enrich and facilitate the experience of the researchers using our finding aids, such as the inclusion of field labels in Spanish. Moreover, future work will hopefully include the application of technologies that could enable multilingual capabilities in our finding aid platform in order to facilitate navigation for different communities of users researching in our collections. Furthermore, we would at some point like to address legacy finding aids for the Latin American collections in order to rewrite the description in Spanish.
If we are truly committed to issues of diversity, equity, and inclusion in archives and libraries, creating multilingual spaces in our institutions and organizations must form part of those initiatives. As noted in the language justice how-to-guide provided by Antena Aire,[7] “…strategies for bridging the divides of language are essential to any endeavor that truly seeks to be inclusive of people from different cultures, different backgrounds, and different perspectives.”[8] By providing finding aids with description that matches the predominant language of the materials, we are respecting the right that everyone has to communicate in the language in which they feel most comfortable.
[4] Dunham, Elizabeth, and Xaviera Flores. “Breaking the Language Barrier: Describing Chicano Archives with Bilingual Finding Aids.” The American Archivist 77 (2), 2014: 499–509. doi:10.17723/aarc.77.2.p66l555g15g981p6.
[6] Sutherland, Tonia, and Alyssa Purcell. “A Weapon and a Tool: Decolonizing Description and Embracing Redescription as Liberatory Archival Praxis.” The International Journal of Information, Diversity, & Inclusion 5 (1), 2021. doi:10.33137/ijidi.v5i1.34669.
[7] “Antena Aire (formerly called Antena) was a language justice and language experimentation collaborative by Jen/Eleana Hofer and JD Pluecker, both of whom are writers, artists, literary translators, bookmakers and activist interpreters. From 2010-2020, Antena Aire used on-the-ground practices building equitable communication as a generative strategies for making artistic works.” http://antenaantena.org
In the wake of the murders of George Floyd, Breonna Taylor, and Ahmaud Arbery, among many others, and in the spirit of protest that followed, the archival community began an earnest conversation about what it could do to promote diversity, equity, and inclusion in our field. This has led to a heightened attention in the creation and/or prioritization of initiatives and projects related to this matter across institutions throughout the country, including Princeton University.
One initiative being implemented in several archival repositories is that of enhancement and redescription work. At Princeton University Library Special Collections, the “Inclusive Description Working Group” has been engaged in archival redescription efforts since its formation in May 2019. Our primary goal is tackling the complex issue of cultural sensitivity in archival description, and to critically rethink our role as archivists in order to create description that is respectful to the individuals and communities who create, use, and are represented in the archival collections we manage. Last year we completed an automated description audit with the goal of identifying existing collections that need work, and our team has been able to work on some redescription projects. One such significant project was undertaken last fall by archival resident Carolina Meneses, who worked under the guidance of Chloe Pfendler on a project to identify and enhance access to the names of women who had previously only been identified by their husbands’ names or as anonymous wives, mothers, and daughters in our Latin American collections. For more information about this project, see here. For more detailed information about this working group, see the following blog post.
Additionally, a newly formed working group within Special Collections, the “Uplifting Silenced Narratives Working Group,” was charged with focusing on uplifting the narratives of marginalized communities in our collections, making them more accessible to researchers, and making our patrons and the campus community more aware of them, as well as seeking to elevate the narratives of marginalized groups and communities that are present in our university and surrounding community. The working group has been meeting bi-weekly since last November, and as we moved forward, it became clear that it was necessary to shift course and depart slightly from the focus laid out in the charge, which will be clearly outlined in the report currently being drafted and to be delivered to the Special Collections Leadership Team next month. The group decided on a new approach whereby we will draft a narrative report with high-level recommendations in three particular areas within the department: Collecting Practices; Archival Processes; and Outreach and Teaching. It will also include the suggestion of a permanent mechanism for staff and patrons to be able to report silenced narratives as they are encountered in our collections.
One way of diversifying the archives is through the collection of oral histories, which provides an effective method of increasing inclusivity and more diverse representations by generating first-hand documentation from traditionally underrepresented groups and communities in the historical record. Additionally, it encourages the community to get involved in the archival process. As Michelle Caswell points out, “These projects also let community members know that archives are not just interested in famous people from the past, but in everyday people in the present.” (1) One commendable oral history project is being led by our own, Valencia Johnson, Annalise Berdini, and Amanda Ferrara, the My Princeton Oral History Project, which aims to create, “…a space for Princeton students who feel left out of the dominant Princeton narrative by capturing and sharing their unique experience.”
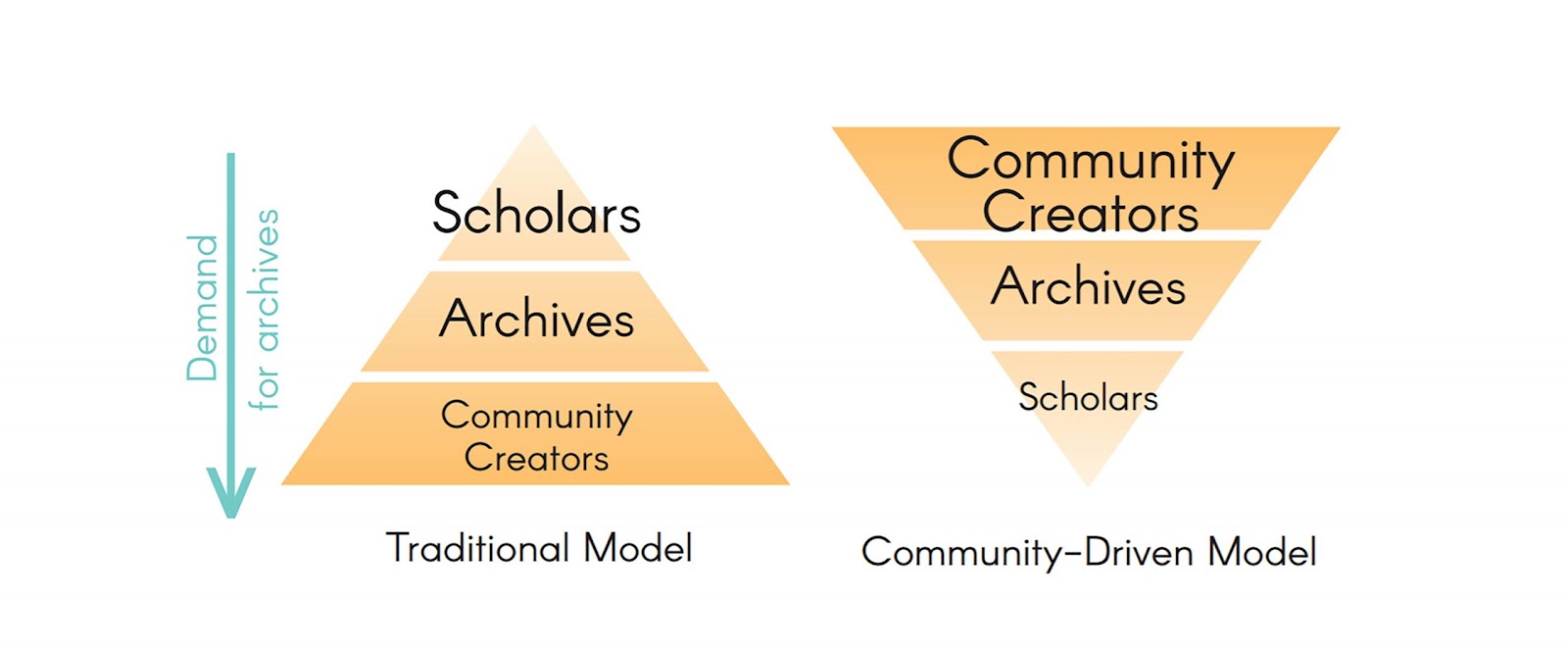
Another initiative that has the potential of significantly diversifying the archives is through the engagement in community archiving practices, which introduces a wider selection of historical materials through collaborations with nontraditional archival institutions. (2) As opposed to uplifting voices of marginalized groups and communities in collections where the creators are predominantly white, one clear advantage of community archiving is that it elevates the voices of those marginalized groups and communities because of their immediate connection as creators of the records, and those who are represented in them. Furthermore, community archives challenge traditional ideas about whose history is important, and redirects the focus of collecting and preserving towards records of ordinary people, instead of simply collecting records of prominent organizations and individuals. As Randal C. Jimerson points out in the article, Archives for All: Professional Responsibility and Social Justice, “It is important to note that while marginalized communities have often lacked representation in the institutional archive, these communities have been actively preserving their own cultures and history outside of the institution.” (3) Working with communities will require changing traditional collecting methods and priorities. As the model created by the UNC Southern Historical Collection’s Community-Driven Archives project illustrates, it will require a shift from a top-down traditional model to a community-driven model. (4)
Furthermore, engagement in community archiving can lead to building a robust post-custodial program. Post-custodial models have been gaining ground in the archival community, and one prominent example is the work being done at the University of Texas Libraries, with projects such as, Archivo Histórico de la Policía Nacional (AHPN), Human Rights Documentation Initiative (HRDI), and the Genocide Archive of Rwanda. In a post-custodial model, creators retain custody of their records, consequently shifting ownership and access to the communities represented, rather than being handed over to larger and wealthier institutions. Post-custodial models are rooted in close collaborations and trusting partnerships, which are guided by equality between the parties, as Lopez Matthews, a librarian at Howard University, notes in the article written by Cynthia Greenlee, Inheritance: The Lost-and-Found History of the Dorsey Scrapbooks, “We came together as equals with a shared goal. That’s not the case with all partnerships. We always ask if we will benefit from them. It’s easier to say that with a smaller, focused partnership … But we don’t need to give our resources to other people to tell our history.” (5) The aforementioned article also accentuates the unfortunate precarious nature of many of these materials, making them highly susceptible to being lost forever. However, advances in digital technology offer larger and wealthier institutions the opportunity to harness technology to establish collaborative and mutual partnerships with community archives. As Sofía Becerra-Licha (2017) notes, “… [technology] presents a significant opportunity for participatory and post-custodial approaches that seek to shift curatorial authority and access to the communities represented.” (6)
A post-custodial approach can also provide an alternative solution to the inevitable issue of limited storage space in archival repositories. The “Storage Space Data Working Group” was charged with formally evaluating the realities of collection growth, and Jen Meyer, on behalf of the group, gave an informative presentation in the Special Collections staff meeting pointing out the growth and capacity projections for the stacks located within the department. As was noted in the presentation, there are various shelf sizes that are close to reaching full capacity, at some point between 2021 and 2024. These include record cartons, Hollinger-size boxes, and oversize flat boxes, the predominant type of boxes used by archivists.
It is encouraging to see the momentum building around issues of diversity, equity, and inclusion in academic institutions across the country. But these initiatives are labor intensive, requiring considerable time, effort, and dedication, which will require a reassessment of existing frameworks of collection development policies and acquisition practices. Yet, it is this current environment, in which the leadership within these institutions is receptive and committed in their pursuit of a more diverse, equitable, and inclusive community, that has presented us with a significant opportunity to prioritize initiatives and projects which can address the long-overdue issue of diversifying the archives in a meaningful and sustainable manner.
(1) Caswell, Michelle. “Seeing Yourself in History: Community Archives and the Fight Against Symbolic Annihilation.” The Public Historian, Vol. 36, No. 4, pp. 26–37 (November 2014). https://doi.org/10.1525/tph.2014.36.4.26
(3) Jimerson, Randall C. “Archives for All: Professional Responsibility and Social Justice.” The American Archivist, vol. 70, no. 2, pp. 252–281 (2007). https://doi.org/10.17723/aarc.70.2.5n20760751v643m7
Educational background: I recently graduated from UCLA’s School of Information Studies with an MLIS, specializing in archival studies. As an undergraduate, I studied comparative literature and Spanish at Smith College.
Previous experience: I’ve been working in libraries and archives in different capacities for a number of years now. Most recently, I interned at the University of California, Irvine’s Special Collections & Archives (SCA). This was an enriching opportunity because I was able to build on previous experience processing born-digital materials — a skill set totally absent from my MLIS program’s curriculum. At SCA, I worked closely with the Assistant University Archivist to develop a new workflow for accessioning born-digital material. I also had the chance to help process a really interesting collection of interactive multimedia CD-ROMs by the feminist media artist, Christine Tamblyn. It was my first time thinking about how to best provide access to obsolete digital art.
Why I like archives/Professional interests:
As the daughter of immigrants to this country, I’ve always felt a strong affinity to history and memory so it is no surprise that I was attracted to the profession from very early on. While studying comp lit as an undergrad, I focused on revivals of language and culture in post Franco Spain.Some of my classes ultimately led me to archival research, which inspired me to seek out internships in archives. At the Trisha Brown Dance Archive, I first encountered the challenges of preserving dance and embodied knowledge.
This curiosity really informed my MLIS studies, which led me to think about how dance and performance is captured, usually video, which is itself ephemeral and unstable. I now see the problems facing digital preservation as an extension of the unique challenges with archiving a performance. I want to continue exploring this dilemma as an archivist and hopefully come up with new ideas to contribute to the profession.
Other interests: I love to cook and try new recipes. I’ve recently been cooking a lot from Falistin by the Palestinian chef, Sami Tamimi. I’m also really into running.
Looking forward to working on the following project(s) while at Princeton:
I’m really excited to do some reference work, which is not something I’ve had the chance to do in previous positions. I think it will especially be interesting to see how this is being done in these times. I’m also curious to learn how Special Collections has been approaching digital processing by helping with updating the digital processing guidelines. I’m also looking forward to working on a redescription project with the Inclusive Description Working Group.
The Inclusive Description Working Group was formed in May 2019, and we are one of several working groups within the Archival Description and Processing Team (ADAPT) at Princeton University Library Special Collections. The group currently includes seven archivists in special collections who volunteered with an interest in changing descriptive practices, and include: Kelly Bolding (chair), Valencia Johnson, Faith Charlton, Phoebe Nobles, Chloe Pfendler, Kalliopi Balatsouka, and Armando Suárez.
The inspiration for the creation of this group began in 2016, with a “description audit project,” led by the Manuscripts Division of Special Collections at Princeton University Library, which aimed to identify problematic description and hidden voices in existing finding aids, and then, in 2017, with the formation of the Anti-Racist Description Working Group, part of the Archives for Black Lives in Philadelphia, some of whose members are part of our processing team. Other inspirations included Michelle Caswell’s article, “Teaching to Dismantle White Supremacy in Archives,” and Temple University’s statement on potentially harmful language (see additional resources for more information).
The group’s primary goal is to tackle the complex issue of cultural sensitivity in archival description, and to critically rethink our role as archivists in order to create description that is respectful to the individuals and communities who create, use, and are represented in the archival collections we manage. With this in mind, we created a set of internal processing guidelines and considerations that will help us and our colleagues describe and process collections with a heightened awareness and empathy.
Some general principles listed in the guidelines are: prioritizing language that individuals and communities would use to describe themselves; balancing the preservation of original context with awareness of the problematic language that can come with it; discontinuing the perpetuation of inequalities in finding aids, such as by avoiding writing biographical notes that elevate the accomplishments of white men and suppress the voices of women, people of color, and other marginalized groups; prioritizing writing or using creator or dealer- supplied description in the language of the creator, materials, and users of a particular collection; and being transparent and accountable about our actions, such as preserving evidence of changes and providing mechanisms for users to report problematic description.
One of our accomplishments this year was the publication of a public-facing statement, called “Statement on Language in Archival Description,” that would let our users and researchers know what we hope to do, what we may or may not be able to do, and why. We are now hoping to add the statement to the home page of our finding aids site, in order for users to find it more easily as they browse through the collections.
In order to address crucial gaps and offensive language in Princeton’s finding aids, the group generated a list of case studies, which document ethically-minded approaches in specific contexts. It is important to note that we do not see the changes we have made as perfect or permanent solutions, but as a place to start, and we plan to keep adding to these case studies as a supplement to our internal processing guidelines. Below are some examples from the case studies:
The Francis C. Brown Collection on Slavery in America collection consists largely of plantation and slavery records assembled by a particular collector who bought the materials from various dealers, and contained item-level descriptions of materials that were transcribed from dealer descriptions written in the mid 20th century. These descriptions often referred to people as “negroes,” “slaves,” or “blacks” and included the names of enslavers but not of the enslaved. The finding aid was updated with the description throughout to refer to people as “enslaved,” as well as to include the names of enslaved people when the names of others mentioned in documents were already included.
Public services staff brought this one to our attention. A folder in the Office of the President Records in the University Archives was labeled with a male professor’s name, “Drewry, Henry N,” but it contained at least as much information about Cecilia Hodges Drewry, a female professor who was married to Drewry. The archivist added the woman’s name, in brackets, to the man’s name, to make her records discoverable while trying to leave clear how the office originally named the file.
The Selected Correspondence of Margaret Randall includes correspondence relevant to gay and lesbian issues, and Randall is out and married to a woman, but the finding aid did not previously identify Randall as a member of the LGBTQ+ community or include terms to help users find these materials. The archivist added a sentence to Randall’s biographical note mentioning her wife, as well as adding subject terms and keywords in the scope and content note and in the list of subject terms.
In a collection of Western Americana Miscellaneous Manuscripts, the archivist added description to position the creators’ perspective, “The collection consists of miscellaneous source material…pertaining to the history of the American West and Southwest in the 19th century, largely from the perspective of white settlers.”
There are many others, but the last example I will mention is from the Ricardo Piglia Papers. Here the processing archivist used the languages of the original material in the finding aid. The collection- and series- level descriptions do appear in English, but titles and more detailed file- and item- level scope and content notes are written in Spanish.
As we move forward, we are pursuing various goals to be undertaken during this year, including conducting automated audits of EAD files, using XQuery, (1) in order to locate potential problems with description in our finding aids; assessing local subject headings usage and gaps; designing and implementing strategies for generating additional staff and public feedback on descriptive practices; as well as begin to seriously discuss which language to use when writing finding aids for archival collections in which most of the materials are not in English.
We recognize that our efforts to create respectful and inclusive description must be an ongoing process, and it’s just one of the ways that the archival field will evolve to be more inclusive, respectful, and culturally sensitive. If the profession wishes to seriously promote and value the ideals of diversity and inclusion that it often seeks to support and encourage, then we all collectively need to confront the biases in archival description and reconsider the language we use when describing materials.
(1) XQuery is a scripting language for querying large sets of XML data. This method was previously used to search the data in our EAD files as part of a project to survey for born-digital materials.
Temple University Libraries. “SCRC Statement on Potentially Harmful Language in Archival Description and Cataloging.” https://library.temple.edu/policies/14
I started my position as the processing archivist for Latin American Manuscripts Collections in Special Collections about a year ago, and so far, I think it has been quite productive, but not without its challenges. Thankfully, I have the privilege of working with a magnificent, collaborative, and forward-thinking group of colleagues. One of our primary goals as stewards of unique archival collections should be to make as much of this material open and accessible to the user and research community as quickly as possible. Therefore, developing sustainable, efficient, and extensible processing practices requires rethinking traditional archival approaches and taking a more forward-thinking and integrated approach.
Unfortunately, large backlogs are quite common in our profession, as it was the case here when I arrived with regards to the Latin American manuscript collections. Backlogs in archival repositories can be traced to lack of staffing resources, as well as traditional archival processing techniques that have primarily focused on extremely detailed item to folder-level archival processing approaches, resulting in only a handful of collections being processed each year. This level of work, combined with an ever-increasing number of acquisitions, has led to an ever-growing number of unprocessed collections that are hidden from the public. One of the primary reasons why I was hired for this position had to do with my past experience dealing with large backlogs. In my two previous positions, I was able to considerably reduce the backlogs at those institutions in a relatively short amount of time, primarily through the application of efficient processing techniques to cut down on the time spent on each collection.
An article entitled, “More Product, Less Process: Revamping Traditional Archival Processing” (1) written in 2005 by Mark A. Greene and Dennis Meissner, had a profound influence in the archival profession. And aside from the overall misunderstandings behind the principles of “More Product, Less Process,” commonly referred to as MPLP, the fundamental takeaway from this approach is that perfect should not be the enemy of good, and that expediting the access to archival materials should be the main goal of our efforts. The Archival Description and Processing Team (ADAPT) in Special Collections has been working on developing guidelines for processing priorities and levels with this approach in mind, which will also support and enhance user access to materials as part of the recently developed strategic mission for Firestone Library. (2)
It is important to note that applying efficient processing techniques does not diminish the quality of archival processing, which should not be measured by the level of detail that is applied, but instead should be evaluated by how effectively a processed collection serves its users, and how wisely an archivist spent the limited resources of the particular repository. Moreover, one has to realize that a finding aid is a living document, as well as a descriptive surrogate for the materials themselves. We can’t do it all and we’ll never be able to find it all, and if warranted, additions/edits can be done after it has, first and foremost, been made accessible to the public. There have been various studies carried out since the publication of the article by Greene and Meissner, such as the survey of American archivists conducted in 2009, (3) focusing on the implementation of MPLP across archival repositories, which have clearly indicated the positive effect in reducing processing backlogs and improving research access.
As a result of implementing these efficient processing practices, I have been able to process several notable collections which are now available to the public. Some of these collections provide a clear contrast on how the organization (or lack thereof) of archival materials differs upon their arrival in our repositories. On one hand, some of the collections are highly organized upon their arrival, such as being placed in distinctive file groups and arranged chronologically and/or alphabetically, with folders clearly labeled, while others arrive in complete disarray, consisting of various types of materials scattered throughout, mostly unfoldered and unlabeled, and without any type of discernable organization.
One of these collections is the Carlos Fuentes Papers. Fuentes (1928-2012) was a Mexican author, editor, and diplomat, who produced an extensive body of work throughout his life. The papers were acquired back in 2013, after Fuentes’ death, and they represented an addition to an already processed collection. It consists of approximately 200 boxes, and materials include notebooks; numerous drafts of novels, short stories, screenplays, articles and essays, speeches, and translations; subject files; press clippings; audiovisual materials; drawings; and printed material. Since the collection was highly organized, it was arranged, for the most part, as received by the repository. Due to its considerable size, much of the processing time was spent performing data entry, reboxing, refoldering, and labeling. Fortunately, I had the valuable assistance of our summer resident, Alice Griffin, and one of our current student assistants, Alia Wood. And after about six years of being hidden in our stacks, this rich collection is now available to the public. Besides having had the privilege of processing the materials of one of my favorite authors while pursuing my undergraduate studies, I also discovered that Fuentes was a talented caricaturist, as seen below.
Caricature by Carlos Fuentes. Drawings and paintings; Carlos Fuentes Papers, C0790, Manuscripts Division, Department of Special Collections, Princeton University Library.
On the opposite spectrum, one of the collections I processed when I first arrived here was one of the most disorganized collections that I had worked on during my professional trajectory as a processing archivist. The papers began to arrive in periodic shipments in December 2018. All in all, a total of 15 large cartons were received. As I began to open the boxes, I immediately realized that the materials were in complete disarray. It consisted of various types of materials scattered throughout without any type of discernable organization (see image below). A few files had been foldered and sometimes labeled, but those were the exception. Additionally, a large number of the materials were undated, untitled, unattributed, and in many cases, drafts and fragments mixed together, which were impossible to separate and identify.
Box with various types of materials scattered throughout .
Therefore, given the disorganized state of the material upon receipt, a functional processing decision had to be made that required the application of current archival processes and best practices to be as efficient as possible with our limited resources and to expedite getting the collection into the hands of users. After performing an overall collection assessment, an arrangement was devised that reflected the sphere(s) of functions and/or activities deemed most appropriate to represent the overall context of the collection. Materials were arranged in file groups by type of materials, consisting of: Notebooks; Diaries and Journals; Writings; Correspondence; Printed Materials; and Other Materials. Furthermore, the writings were subdivided into the following file groupings: Poetry; Short Stories and Novels; Articles and Essays; Scripts; Translations; Other writings; and Writings by Others.
Another issue was how to proceed with the arrangement of the correspondence (see image below). There were about four large cartons containing correspondence, and after looking at other finding aids in the Latin American literary collections, I saw that arrangement in the past had been primarily done using the traditional processing approach of arranging them alphabetically. That particular arrangement might be feasible if the correspondence had arrived in somewhat discernable groupings, but in this particular situation, alphabetically arranging the correspondence would have taken a significant amount of time and effort. One of the most important things we do as archivists is processing, but it is also one of the most expensive, therefore, it is essential to take into consideration the amount of time and effort that we perform from the outset. If in the future, evidence warrants the re-processing of certain portions of the collection, we can always go back and revisit, but the time spent from the onset can never be regained.
I therefore decided that the correspondence was best arranged chronologically (by decades), which still took a considerable amount of time, almost a month. Only the correspondence that was received in identifiable groupings or was easily identified was separated and arranged by correspondent. Additionally, while separating the correspondence by decades, careful attention was undertaken in order to establish access points for prevalent and particular names found throughout.
Box with correspondence.
Another important consideration in the archival profession is the principle of respect des fonds, which is the basis of archival arrangement and description, and refers to the combined principles of provenance and original order. The latter, as defined by the Society of American Archivists (SAA), “means that the order of the records that was established by the creator should be maintained by physical and/or intellectual means whenever possible to preserve existing relationships between the documents and the evidential value inherent in their order.”(4) Taking this principle into consideration, how much intervention should an archivist perform during processing? As an archivist, one has to be cognizant of how the records were created. The inherent nature of personal papers does not only simply document facts, but also the character, and other aspects of an individual’s inner life. We should not think that all archival materials will be used to simply indicate facts, dates, activities, and functional activities to researchers and historians, but might also shed light on the character of the creator.
Fundamentally, archives are used and archivists are not only guardians of information, we also have to be effective at making that information available for the public. We have to essentially shift our perception of what “processed” looks like and means, in order not to let perfection be the enemy of “good enough,” which has greatly hindered access to the resources that we are committed to. As processing archivists, it is quite gratifying to see the final results of our work being accessible to the public. By making decisions based on the mission, audience, and current resources of the institution, we can better serve our patrons and thus reduce our backlogs and provide access to our valuable collections in a timely manner for the benefit of the people.
(1) Mark Greene and Dennis Meissner (2005) More Product, Less Process: Revamping Traditional Archival Processing. The American Archivist: Fall/Winter 2005, Vol. 68, No. 2, pp. 208-263.
Princeton University Library’s Department of Special Collections is excited to offer the Archival Residency for Manuscripts Division Collections again this year. The residency provides a summer of paid work experience for a current or recent graduate student interested in pursuing an archival career.
Residency Description: The 2020 Resident will primarily gain experience in technical services, with a focus this year on arrangement and description of manuscript collections, including hybrid collections with born-digital and audiovisual materials. The Resident will also assist with in-person and/or remote reference and other public services related projects. The Fellow will work under the guidance of the team of processing staff responsible for collections within the Manuscripts Division, including the Lead Processing Archivist, Project Archivist for Americana Manuscripts Collections, Processing Archivist for General Collections, and the Latin American Processing Archivist, as well as the Reference Professional for Special Collections.
The Manuscripts Division is located in Firestone Library, Princeton University’s main library, and holds over 14,000 linear feet of materials covering five thousand years of recorded history and all parts of the world, with collecting strengths in Western Europe, the Near East, the United States, and Latin America. The Resident will primarily work with the Division’s expansive literary collections, the papers of former Princeton faculty, and collections relating to the history of the United States during the 18th and 19th centuries.
The ten- to twelve-week residency program, which can begin as early as May, provides a stipend of $950 per week. In addition, travel, registration, and hotel costs to the Society of American Archivists’ annual meeting in August will be covered by Princeton.
Requirements: This residency is open to current graduate students or recent graduates (within one year of graduation). Applicants must have successfully completed at least twelve graduate semester hours (or the equivalent) applied toward an advanced degree in archives, library or information management, literature, American history/studies, or other humanities discipline, public history, or museum studies; a demonstrated interest in the archival profession; good organizational and communication skills; and the ability to manage multiple projects. At least twelve undergraduate semester hours (or the equivalent) in a humanities discipline and/or foreign language skills (particularly Spanish-language reading skills) are preferred.
The Library highly encourages applicants from under-represented communities to apply.
To apply: Submit a cover letter, resume, and two letters of recommendation addressed to the search committee at mssdiv@princeton.edu with the subject line “Archival Residency.” Applications must be received by Monday, March 9th, 2020. Video interviews will be conducted with the top candidates, and the successful candidate will be notified by April 3rd.
Please note: University housing will not be available to the successful candidate. Interested applicants should consider their housing options carefully and may wish to consult the online campus bulletin board for more information on this topic.