
Team 13 – CAKE
Connie (task description, interface design, blog post), Angela (task analysis, interface design), Kiran (contextual inquiries, interface design), Edward (contextual inquiries, task description)
(in general, we collaborated on everything, with one person in charge of directing each major component)
Problem/Solution
3d modeling is often a highly unintuitive task because of the disparity between the 3d work space and the 2d interface used to access and manipulate it. Currently, 3d modeling is typically done on a 2d display, with a mouse that works on a 2d plane. This combination of two 2d interfaces to interact with a 3d one (with the help of keyboard shortcuts and application tools) is hard to learn and unintuitive to work with. A 3d, gesture-based interface for 3d modeling combines virtual space and physical space in a way that is much more natural and intuitive to view and interact with. Such a system would have less of a learning curve and facilitate more efficient interactions in 3d modeling.
Contextual Inquiry
Users
Our target user group is limited to individuals who regularly interact with 3d data and representations, and who seek to manipulate it in some way that depends on visual feedback. These are the people who would find the most practical use out of our system, and who would benefit most in their workflow.
Our first user was a professor in Computer Graphics. He has been doing 3D graphics for many years and has some experience with many different programs and interfaces for manipulating 3D data. However, he stated that he didn’t personally do heavy 3D tasks anymore (at least with the interface he showed us); however, he often shows new students how to use these interfaces. He likes exploring applications of 3D graphics to the humanities, such as developing systems for archaeological reconstruction. He does not focus much on interfaces, as he believes that a good spatial sense is more useful than an accessible interface (though for the applications that he develops, he is happy to alter the interface based on user feedback).
Our second user was a graduate student in Computer Graphics who has been at Princeton for several years. He has experience in 3D modelling using Maya, and his primary research project related to with designing interfaces for viewing and labelling 3D data. Because of his research and undergraduate background, he had a lot of background in basic 3D viewing manipulations and was very adept at getting the views he wanted. His priority for his interfaces was making them accessible to other, inexperienced users; this was because his research is supposed to be used for labelling objects in point clouds (which could be outsourced). In terms of likes and dislikes, he stated that he did not really get into modelling because it required too much refinement time and effort.
Our third interviewee was an undergraduate computer science student from another university. He has experience in modelling and animation in Maya, and did so as a hobby several years ago. He has taken courses in graphics and game design, and has a lot of gaming experience. However, his experience with Maya was entirely self-taught, and he acknowledged that his workflows were probably very unlike those of expert users. Because of this, his priorities were not speed or accuracy of tasks, but being able to create interesting effects and results. He was happiest when experimenting with the sophisticated, “expert” features.
Interviews
We observed our first two CI subjects in their offices, with their own computers, monitors, mice, and keyboards. They were usually alone and focused on their task while using their systems. The last user did his modelling in his home or dorm room, generally alone or working with friends. We asked our subjects to show us the programs that they used to do 3D manipulation/modelling, and perform some of the tasks that they normally would. Following the master-apprentice model, we then asked them to go over the tasks again, and explain what they were doing as if they were training us to perform the same things. After this, we tried to delve a bit deeper into some of the manipulations that they seemed to take for granted (such as using the mouse to rotate and zoom) and have them try to break down how they did it, and why they might have glossed over it. Finally, we had a general discussion about their impressions about 3D manipulation in general, especially focusing on other interfaces they had used in the past and the benefits/downsides compared to their current programs.
The most common universal task was viewing the 3D models from different perspectives – each user was constantly rotating the view of the data (much less frequently panning or dollying). Another fairly common task was selecting something in the 3D space (whether a surface, a point, or a model). After selection, the two common themes were some sort of spatial manipulation of the selected object (like moving or rotating it), or non-spatial property editing of the selected object (like setting a label or changing a color). It seems that the constant rotation was helpful for maintaining a spatial sense of the object as truly 3D data, since without the movement it could simply look like a 2D picture of it (this is especially true because you can translate or zoom a single 2D image without gaining any more 3D information, whereas rotation is a uniquely 3D operation).
Essentially all of the operations we observed being performed fell into the categories mentioned above.
Our first user’s program was used for aligning several 3D scans to form a single 3D model; his operations involved viewing several unaligned scans, selecting a single one, and moving/rotating it until it was approximately aligned with another model. We noted that he could not simultaneously change views and move the scans, so he often had to switch back and forth between changing views and manipulating the object.
Our second interviewee showed us his research interface for labeling point cloud data. The point cloud data labeling application was really primarily about viewing manipulations: the program showed the user a region of a point cloud, and the user would indicate whether it was a car, streetlight, tree, etc. The user only really had to rotate/pan/zoom a little bit if necessary to see different views of the object under consideration, and sometimes select pre-segmented regions of the point cloud.
The Maya workflow was far more complex. For example, the skinning process consisted of creating a skeleton (with joints and bones), associating points on the model surface with sections of the skeleton, and then moving the joints. The first part was very imprecise, since it involved repeatedly creating joints at specific locations in space. After creating a joint, the user had to carefully drag it into the desired position (using the top, side, and front views). The user thought this was rather tedious, although the multiple views made it easy to be very precise. He did not go into much detail about the skinning process, using a smart skinning tool instead of “painting skinning weights” on the surface (which basically looked like spray-painting the surface with the mouse). Finally, joint manipulation just involved a small sphere around the joint that had to be rotated using the mouse. He also described how the advanced features generally worked (but didn’t actually show them) and described them as generally involving selecting a point and dragging it elsewhere, or setting properties of the selected object.
Task Analysis
- Who is going to use the system?
Our system can be used in 3D Modelling: Game asset designers, film animators/special effects people, architectural designers, manufacturing, etc. More generally, we can use our system for basic 3D Manipulation and viewing – Graphics research, medical data examination (e.g. MRI scans), biology (examining protein/molecular models), etc. People in these fields generally are college educated (since the application fields are in research, industrial design or media), and because of the nature of the jobs they will probably have experience with software involving 3D manipulation already. They certainly must have the spatial reasoning abilities to even conceptualize the tasks, let alone perform them. It may be common for users to have more artistic/design background in non-research application contexts. We imagine that there is no ideal age for our system; because of the scope of the tasks we expect that the typical user will be teenaged or older. Additionally, our system requires two functioning eyes for the coupling of input-output spaces to be meaningful. - What tasks do they now perform?
In 3D modeling, they take 3D scans of models and put them together to form coherent 3D models of the scanned object. They also interact with 3D data in other ways (maps, point cloud data representations of real life settings), create and edit 3D objects (models for feature films and games: characters, playing fields), define interactions between 3D objects (through physics engines, for example, define actions that happen when collisions occur), and navigate through 3D point-clouds (that act as maps, of, say a living room: see floored.com). - What tasks are desired?
On a high level, the desired tasks are the same as the tasks they now perform; however, performing some of these tasks can be slow or unintuitive, especially for those who are not heavy users. In particular, manipulation of perspective is integral to all of the tasks mentioned above, and manipulating 3D space with 2D controls is not intuitive and often difficult to learn so that operations run smoothly. - How are the tasks learned?
Our first interviewee highlighted the difference between understanding an interface (getting it) and being good at using it intuitively (grokking it). The first of these involves learning how things work: right click and drag to translate, click and drag to rotate, t for translation tool, etc. These facts are learned through courses, online training and tutorials, and mentorship. The second part can only be done through lots of practice and actual usage to achieve familiarity with the 3D manipulations. Our first interviewee noted that, after learning gaining the spatial intuition for one type of interface, other such tasks and interfaces often become much easier to grok. - Where are the tasks performed?
Tasks are performed on a computer, typically in offices, as they are often a part of the user’s job. Animators generally work in very low lighting, to simulate a cinematic environment. People are free to stop by to ask questions, converse, etc. — which interrupts the task at hand, but does not actively harm it, just as with other computer-based tasks. Also some people might design at home for learning, or personal app or game development. - What’s the relationship between user & data?
The user wants to manipulate the data (view, edit, and create it). Currently, most 3D data is commercial, and the user is handling the data in the interests of a company (e.g. animated models for films), or for research purposes with permission given by a company (e.g. Google Streetview data). Some of it can be personally acquired, e.g. with kinect. Some users create the data: for example, designing game objects in video games, or 3D artwork for films. - What other tools does the user have?
Manipulation of 3D data requires tools with computing ability — with a computer, there are other interfaces, such as through the command line, to select and move objects (specifying exact locations). With animation, animators can use stop-motion animation, moving actual objects incrementally between individually photographed frames. In general, a good, high-resolution display is a must. Most users do their input via mouse and keyboard. There are some experimental interfaces that use specialized devices such as trackballs, 3D joysticks, and in-air pens. Many modellers also use physical models or proxies to approximate their design, e.g. animators might have clay models and architects might have small-scale paper designs. - How do users communicate with each other?
Users communicate with each other both online and in person (depending on how busy they are, how close they are located) for help and advice; they also report to managers with progress on their tasks. (for instance there are developer communities for specific brands of technology http://forum.unity3d.com/forum.php?s=23162f8f60e0b03682623bf37fd27a46 for example ).
In general, modelling has not been a heavily collaborative task. 3D modellers might have to discuss with concept artists on how to bring their ideas into the computer. Different animators might be working on different effects on the same scene in parallel, such as texturing and animating, or postprocessing effects. - How often are the tasks performed?
Animators undertake 3D manipulation jobs daily — for almost the entire day (and during this time, continually manipulating view and selecting objects to create and edit the 3D data). Researchers, on average, tend to perform the tasks less frequently. The professor we interviewed rarely manipulates the 3D data himself (except for demos); the graduate student still interacts with the data daily, as his research project is to design an interface that involves 3D interaction. In terms of individual tasks, the functions that are performed most frequently are by far changing the perspective. This happens essentially continuously during the course of the 3D manipulation session, almost such that it doesn’t feel like a separate task. Next most common is selecting points or regions, as these are necessary for most actual manipulation operations. - What are the time constraints on the tasks?
As changing perspective is such a common task, required for most operations, it is a task which users will not want to spend much time on (given that their goals are larger-scale operations). For operations which they are aware require a significant amount of time (e.g. physical simulations, rendering), they are willing to wait, but would certainly prefer them to be faster — they are also more willing to wait for something like a fluid simulation if they are aware of what the end result will generally be like (which is another problem). - What happens when things go wrong?
Errors in modelling can generally be undone, as the major software keeps track of change history for each individual operation. Practical difficulties may arise in amount of computer resources required to create a model of high resolution.
Task Descriptions
- (Easy) Perspective Manipulation
This task classically involves rotating, panning, and zooming the user’s view of the scene to achieve a desired perspective or to view a specific part of the scene/model. Perspective manipulation is a fundamental, frequent task for every user we observed. It seems to serve the dual purpose of preserving the user’s mental model of the 3D object, as well as presenting a view of the scene where they can see/manipulate all the points necessary to complete their more complex tasks.
Currently, this task has a large learning curve, but once people are used to it, it becomes easy and natural; the only hurdle is that with current interfaces, it is not possible to change this while performing another mouse-based task. With our proposed interface, we first propose to separate the two purposes of preserving spatial sense and presenting manipulable views. With a stereoscopic, co-located display, we make preserving spatial sense almost a non-issue with no learning curve, especially with head-tracking. We also believe that using a gestural, high degree-of-freedom input method can allow for more intuitive camera control, equating to an easier learning curve. We also note that using gestural inputs will allow users to perform perspective manipulation simultaneously with other operations, which to us is more in line with how the users conceive of this (as a non-task, rather than a separate task). - (Medium) Model Creation
This task is to create a 3D mesh of some desired appearance. Depending on the geometry of the desired model, it can be created by starting off by combining and editing some simple geometry (spheres, ellipsoids, rectangular prisms), or modelled off of a reference image, from which an outline of the model can be drawn, extruded, and refined to create a model. The task involves object (vertex, edge, face) selection, creation, and movement (using perspective manipulation to navigate to the location of the point of interest), and typically involves many iterations to achieve the desired look or structure.
Game designers and movie animators perform this task very often, and a current flaw of the system is that the creation of a 3D shape happens in a 2D environment. We anticipate that creating a 3D model in 3D space will be much more intuitive. - (Hard) 3D Painting
Color and texture on 3D models gives a sense of added style and presence. Many artists use existing images to texture a model, e.g. an image of metal for the armor of a model of a medieval knight, as it is relatively easy and efficient. However, when existing images do not suffice for texturing an object, an artist can paint the desired texture onto the object. Such 3D painting is a very specialized skill, as painting onto a 3D object from a 2D plane is very different from traditional 2D painting (many artists who are skilled in 2D painting are not in 3D painting, and vice versa) and can be unintuitive. Major platforms for 3D painting project a 2D image onto the object, which can cause unexpected distortions for those unfamiliar with the sense of operation. In our interface, we intend for users to be able to paint onto an object in 3D space with their fingers.
Interface Design
Functionality
We intend to include functionality for most basic types of object manipulation (rotation, translation, scale), which will be mapped to specific gestures, typically with both hands and arms. We also want to allow for more precise manipulation such as selection/distortion and 3d painting, which involve gestures using specific fingers in more precise movements. To add control and selection capabilities, we hope to incorporate a tablet or keyboard, perhaps to change interaction modes or select properties such as colors and objects. Together, these will encompass a considerable portion of the functionality that basic 2d interfaces provide currently, while making the interaction more intuitive because it is happening in 3d space.
Storyboards

Easy task: Perspective Manipulation

Medium task: Model Creation

Hard Task: 3D Painting
System Sketches
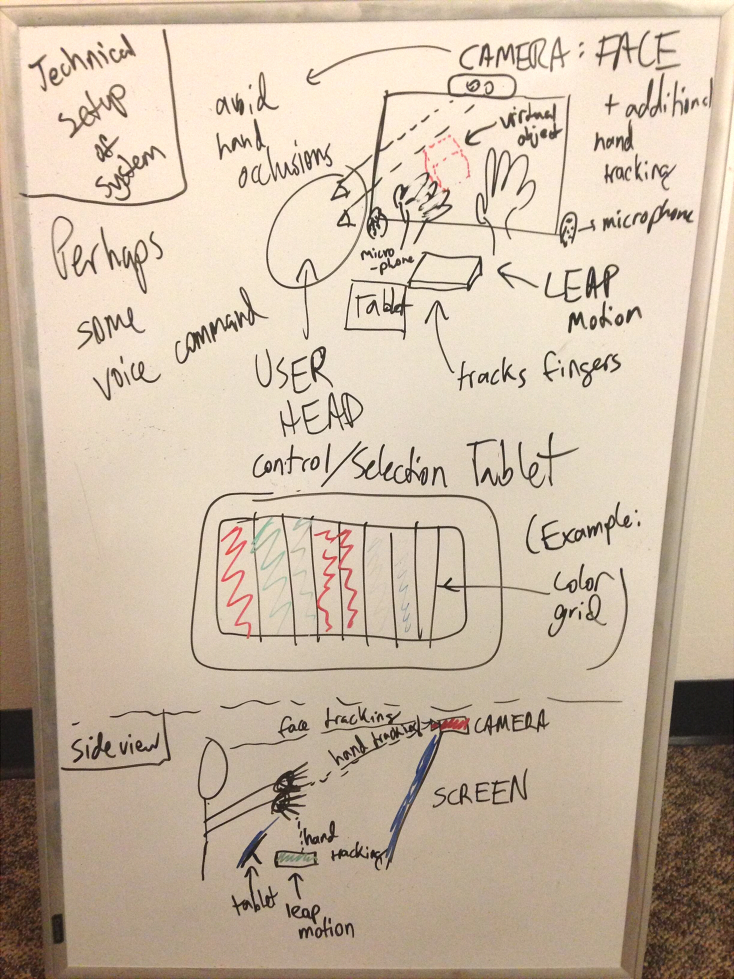
Top: Front view of the system, including all component devices. Middle: Tablet (or keyboard) for additional selection and control, like mode or color change. Bottom: Side view of system, showing the devices and basic form of interaction.
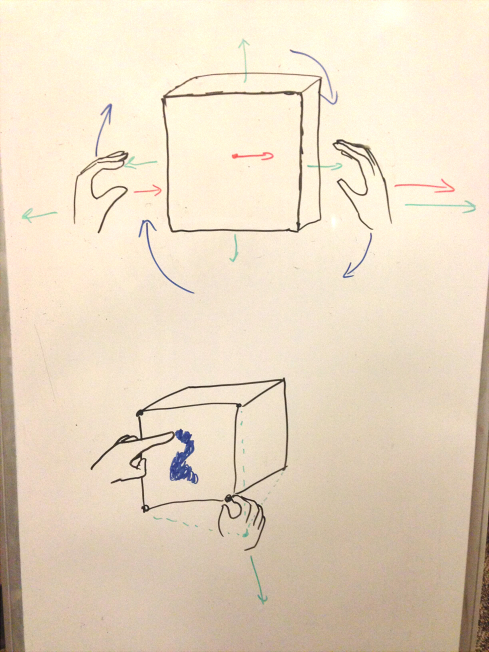
Top: basic ways for the user to interact with the system using hand gestures. Bottom: More precise gestures and interactions that require greater accuracy. (Not shown: control mechanisms such as a tablet or keyboard to switch between them, or provide extra choices for functionality)