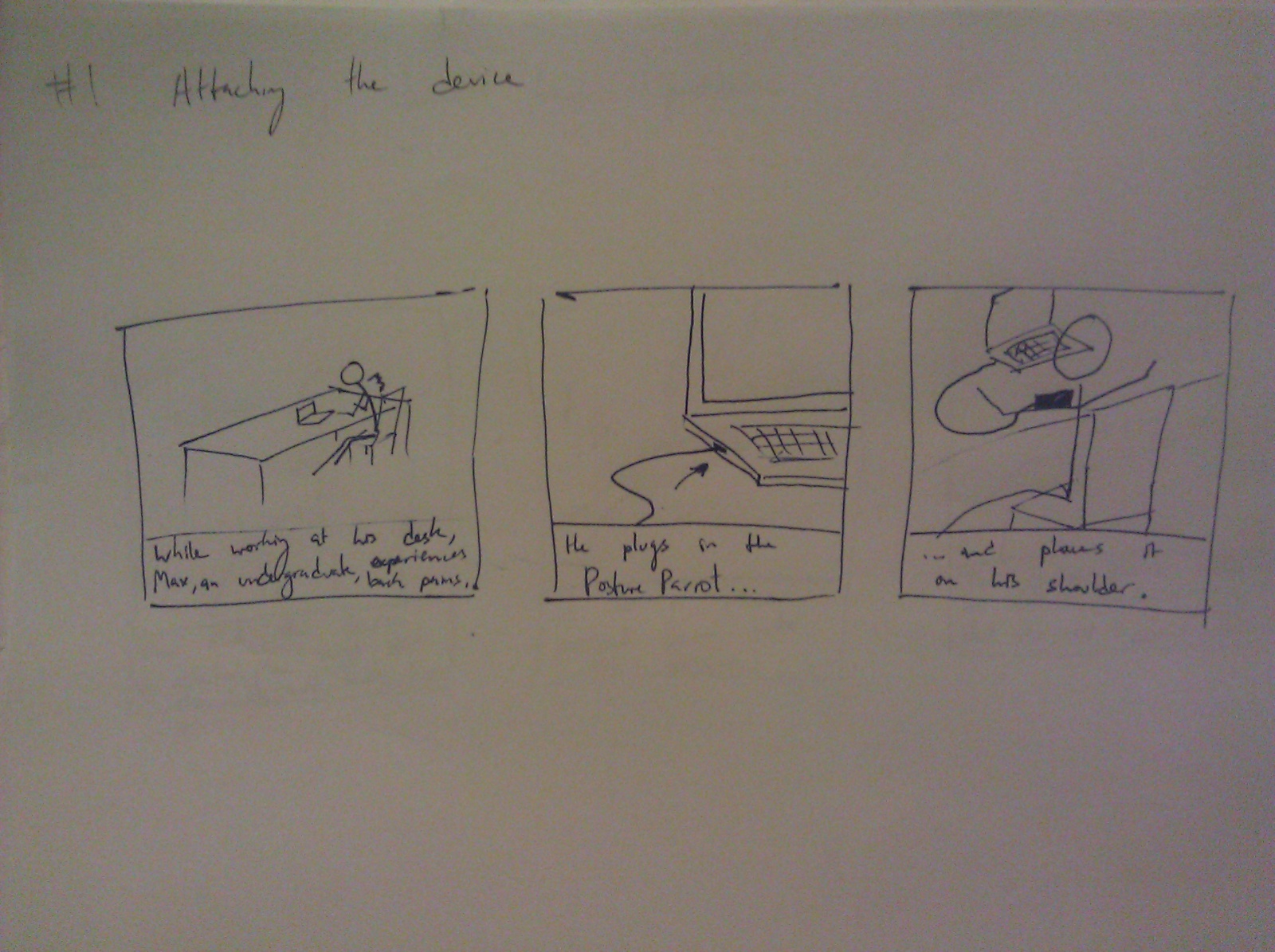
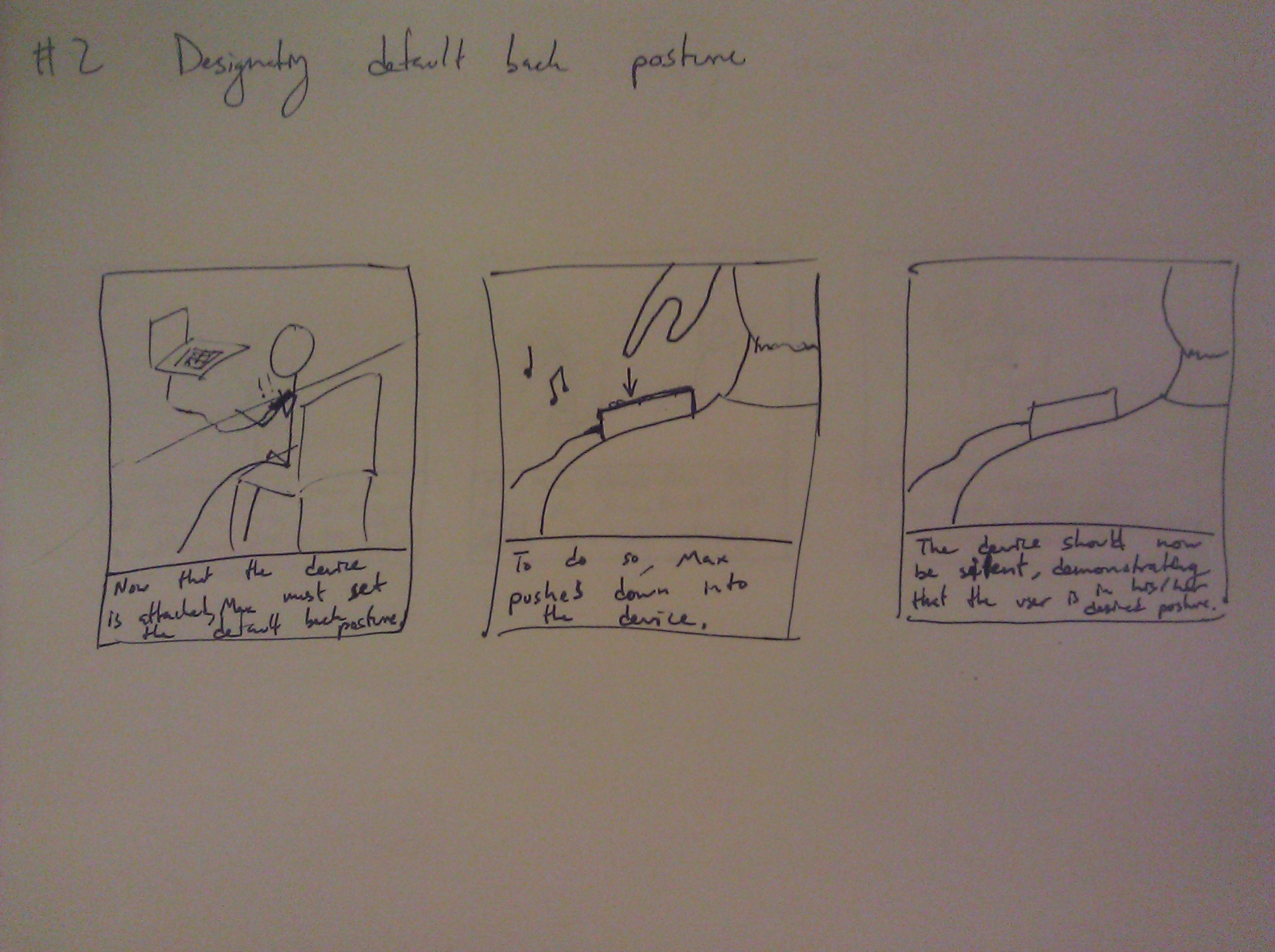
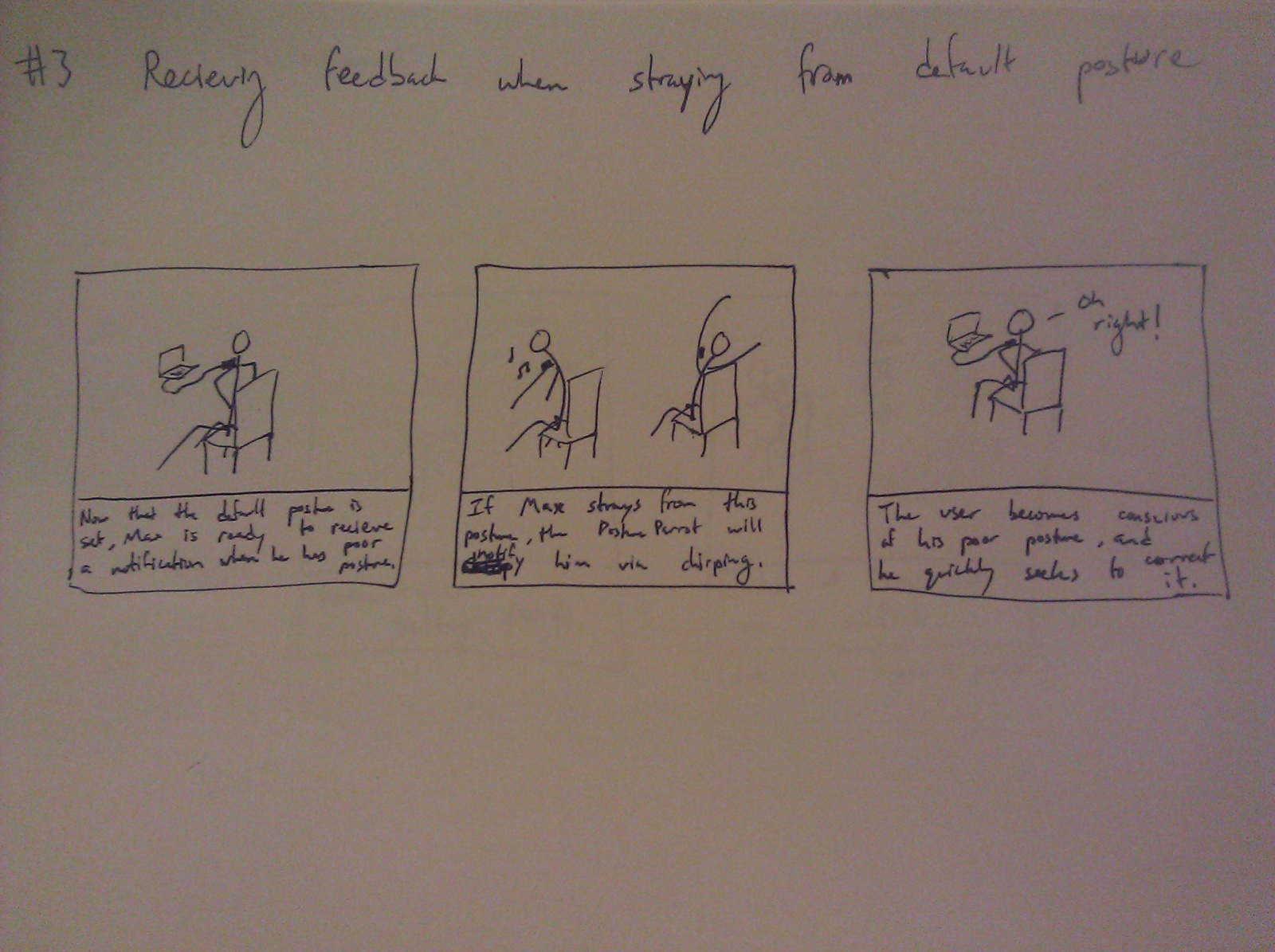
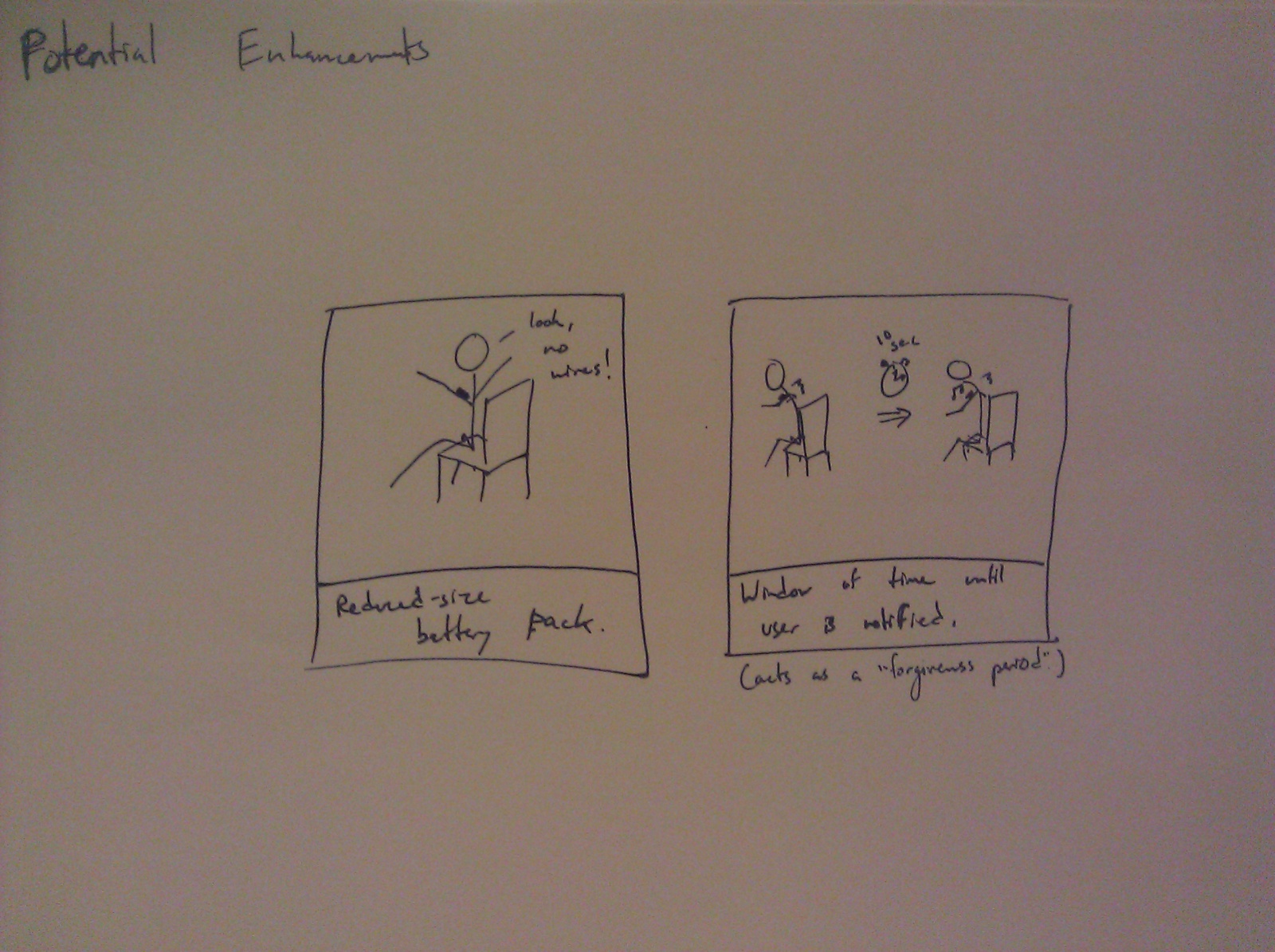
Group 15 – Lifehackers
Prakhar Agarwal, Colleen Carroll, Gabriel Chen
Project Summary:
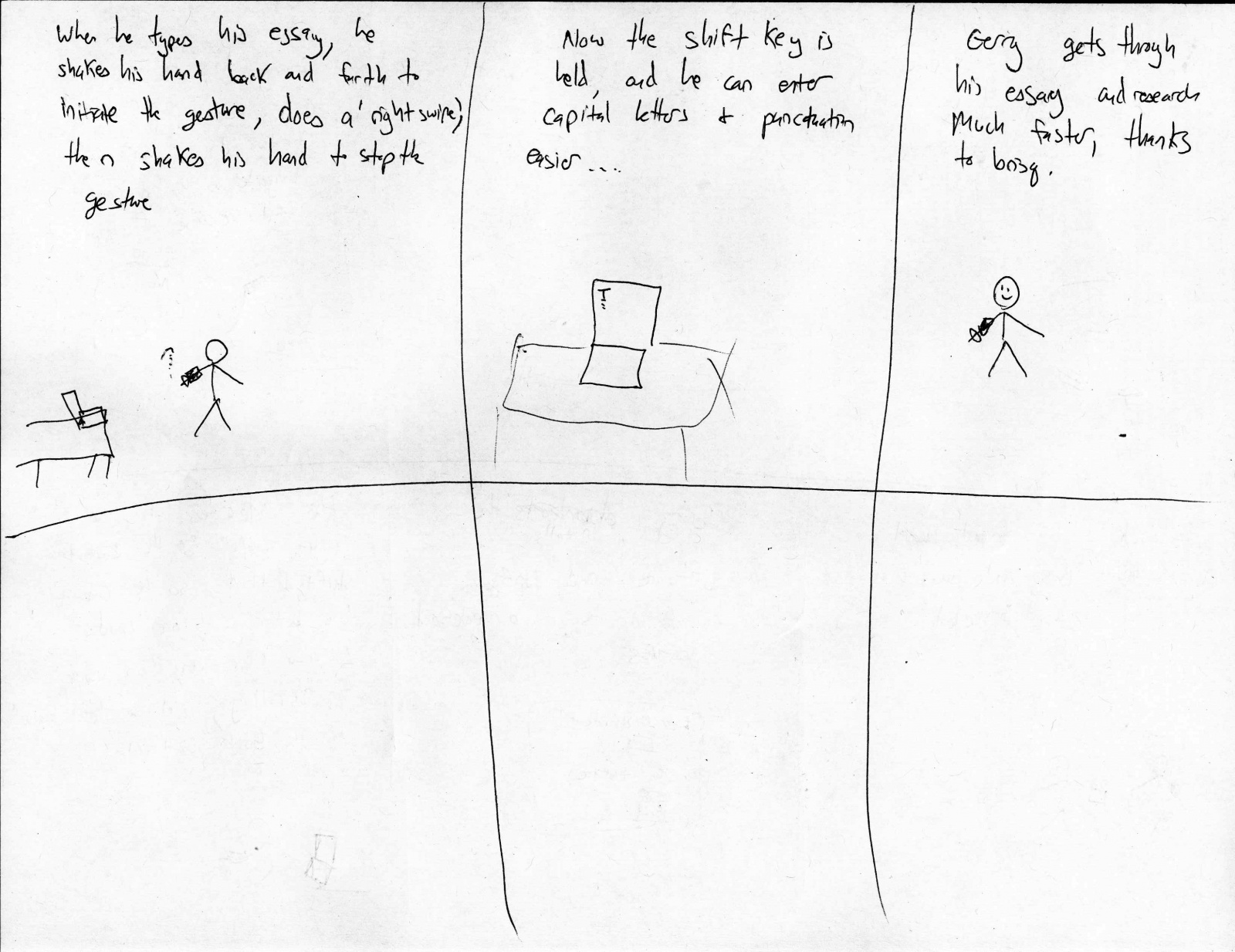
Our project is a glove that allows us to control (simulated) phone actions by sensing various hand gestures.
Tasks Supported:
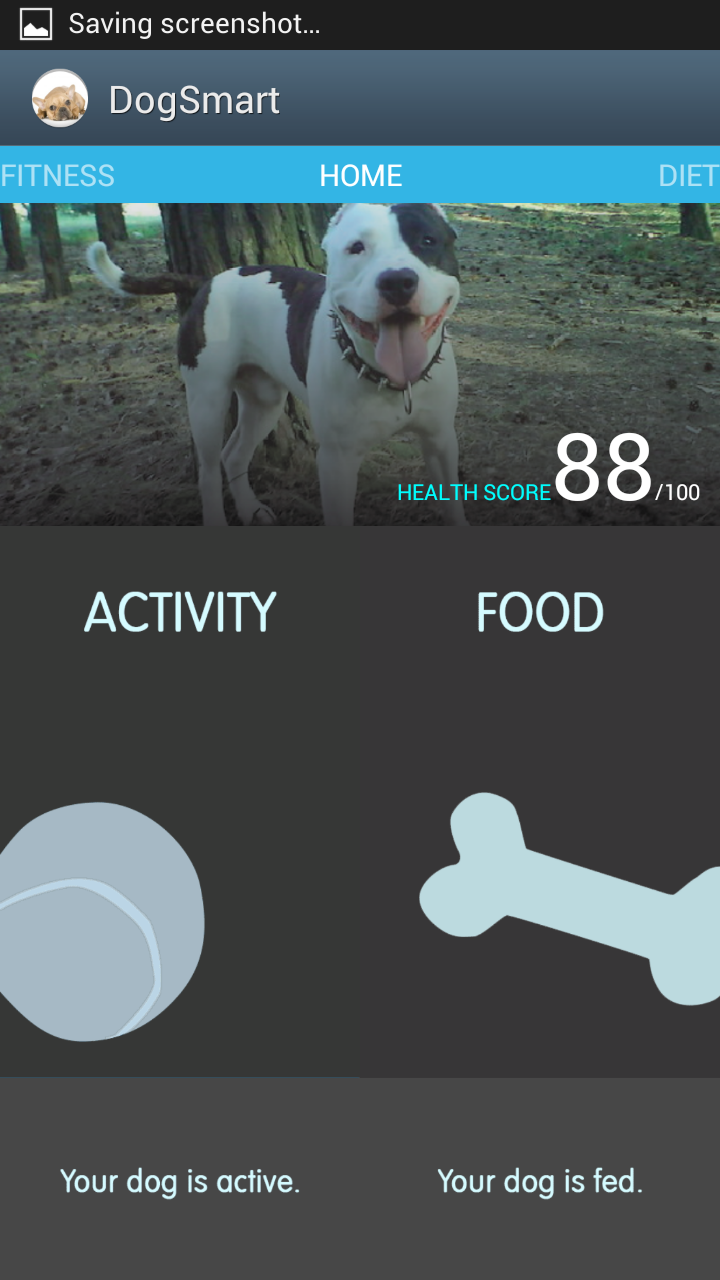
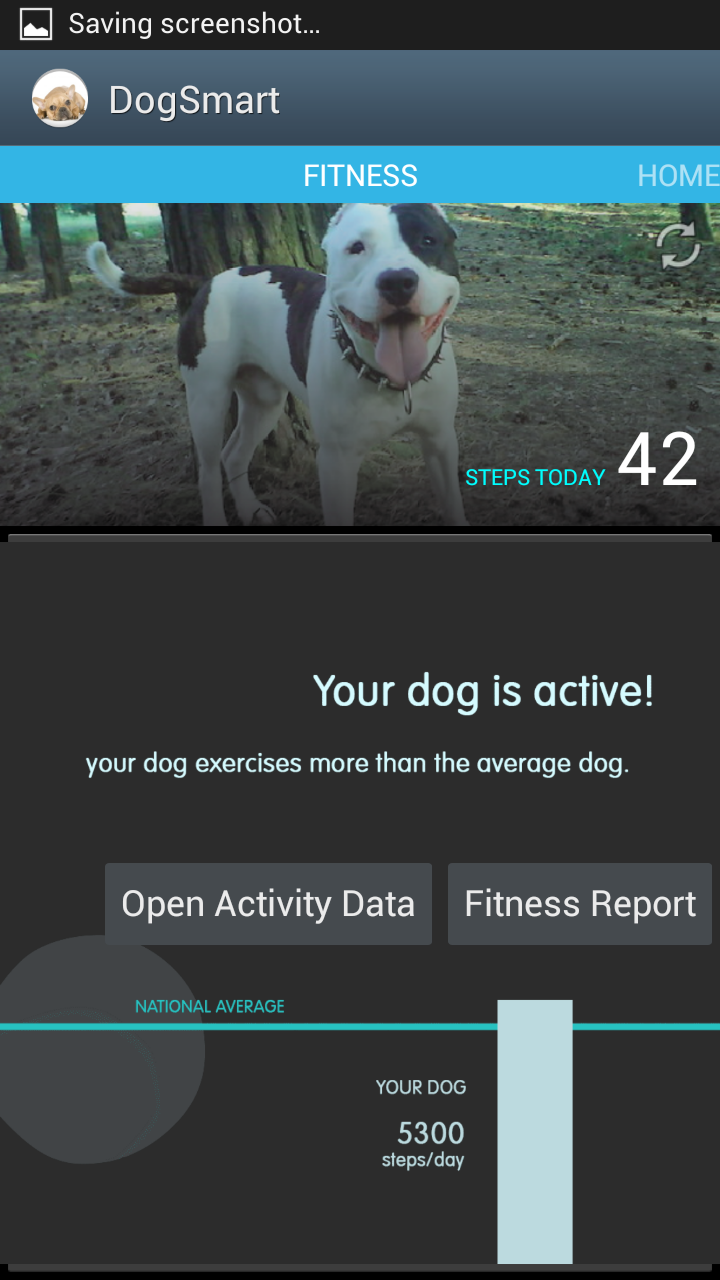
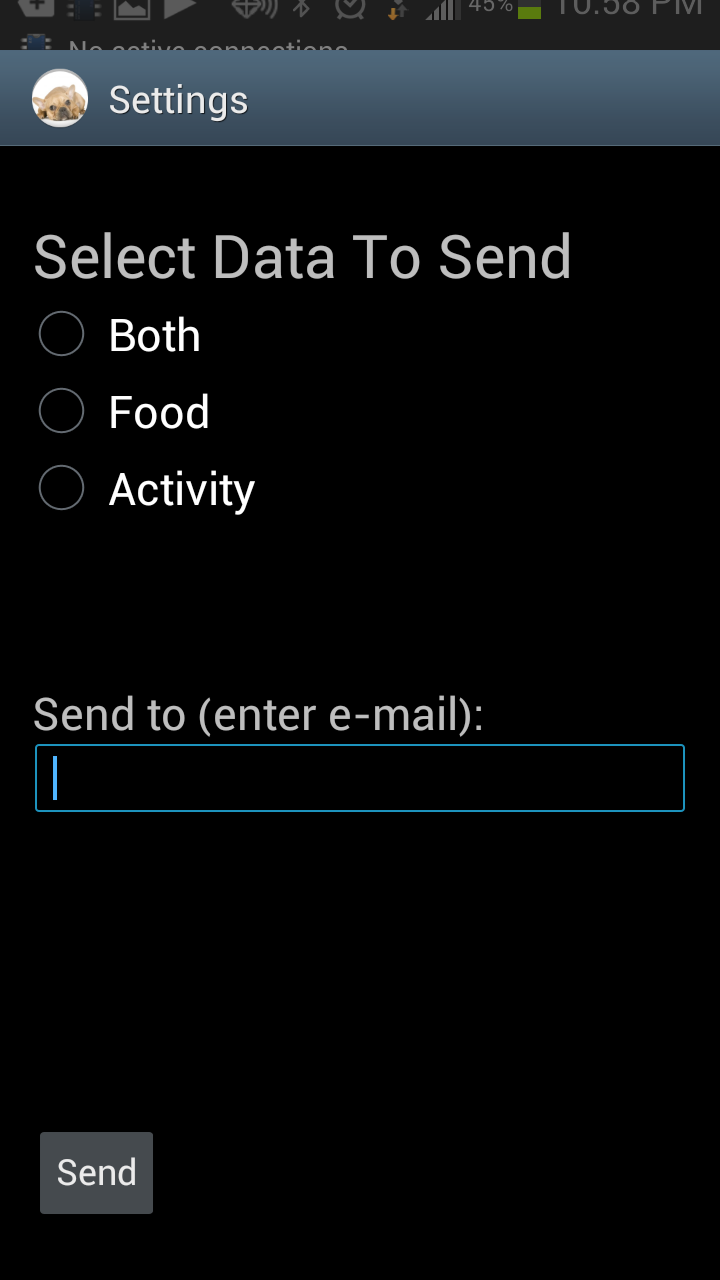
The first and easiest task we implemented is picking up a phone call. A user simply puts his hand into the shape of a phone to pick up a call and then can do the ‘okay’ hand motion in order to end the call. Our second task is more difficult as there are more commands and gestures to be recognized. This task allows users to control a music player with the glove. By using a preset set of hand motions, a user can play and pause music, navigate between a number of tracks and adjust the volume of the music that is playing. Finally, our last task involved allowing users to set a custom password represented by a series of three custom hand gestures, which the user can then use to unlock his phone. This is the most difficult task as it involves setting gestures oneself.
Task Changes:
For the most part, our tasks have stayed the same as they were in the lo-fi prototyping stage. From talking to users during testing, we found that these seemed to be among the simple functions that users would like to be able to control while walking outside in the cold with gloves. Also, these three tasks gave us a nice range of implementation and usability difficulty to play with. One change we did make was setting the number of gestures required for a password to three. We found that allowing the user to add more gestures made both implementation and usability for the end user more confusing.
photos of the working prototype:





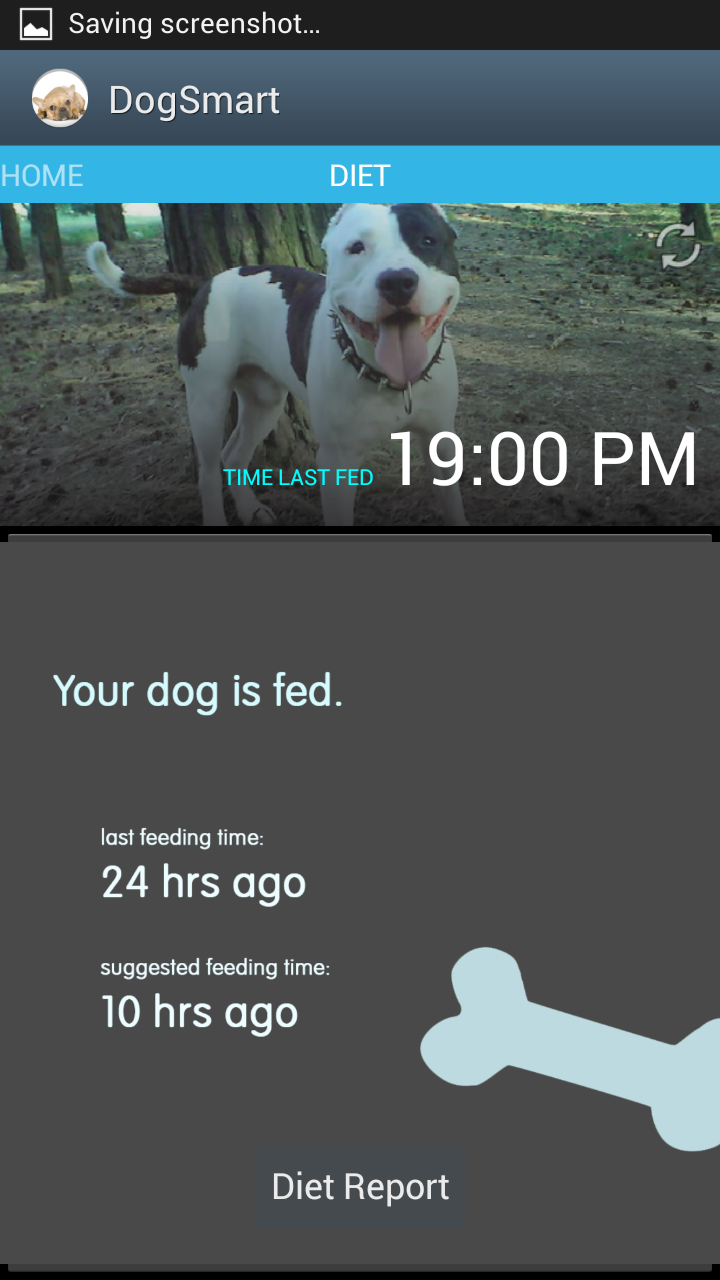
Revised Interface Design:
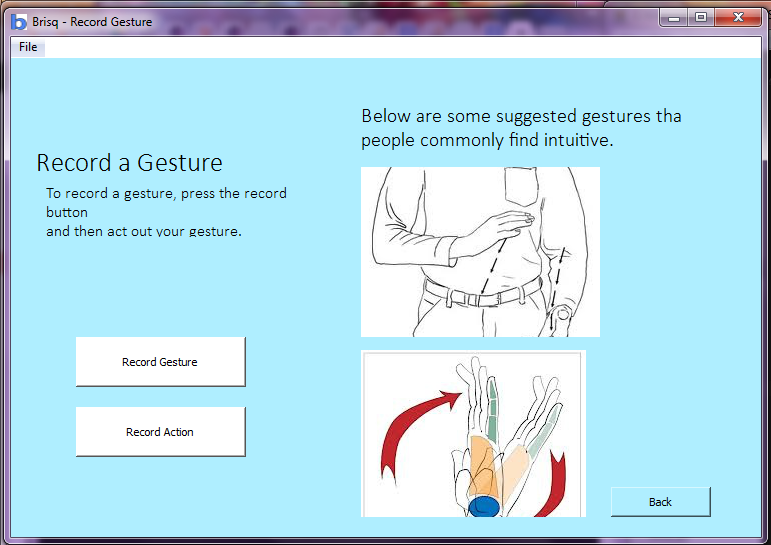
We decided to make a number of changes to our system based on feedback from P4. We decided to put the flex sensors on the back of the glove rather than in the palm. During P4, we found that finger flexibility was a problem for some users because the cardboard “sensors” limited range of motion; this proved to be even more of a problem when we used the real sensor which came with an additional mess of wires, and so we decided to change our design slightly. Of course, these physical changes also mean that a number of the gestures we had previously proposed changed. The updated gestures for in built functions are shown below:








We also imagine that the glove would in the future be wireless and the hardware would be small and secure enough to fit on the glove. In this iteration, we decided not to have an accelerometer on the glove. We found that there was enough flexibility in the number and types of gestures that we could make without one, and adding the accelerometer made the glove very clunky and difficult to use. For future iterations, we have considered using the built in accelerometer in smartphones to add to the variety of gestures that can be issued with the glove. Even our built in gestures could have motion (as pictured below). We also have one task that we left off of this project, but was in our original plan, the voice command. This gesture, which we imagine to be a “V” with the index finger and middle finger (as pictured below) would initiate the voice command on the smartphone so that a user has access to tasks such as sending texts,making a call, or setting reminders, without having to take off the gloves.
sketches of unimplemented features:


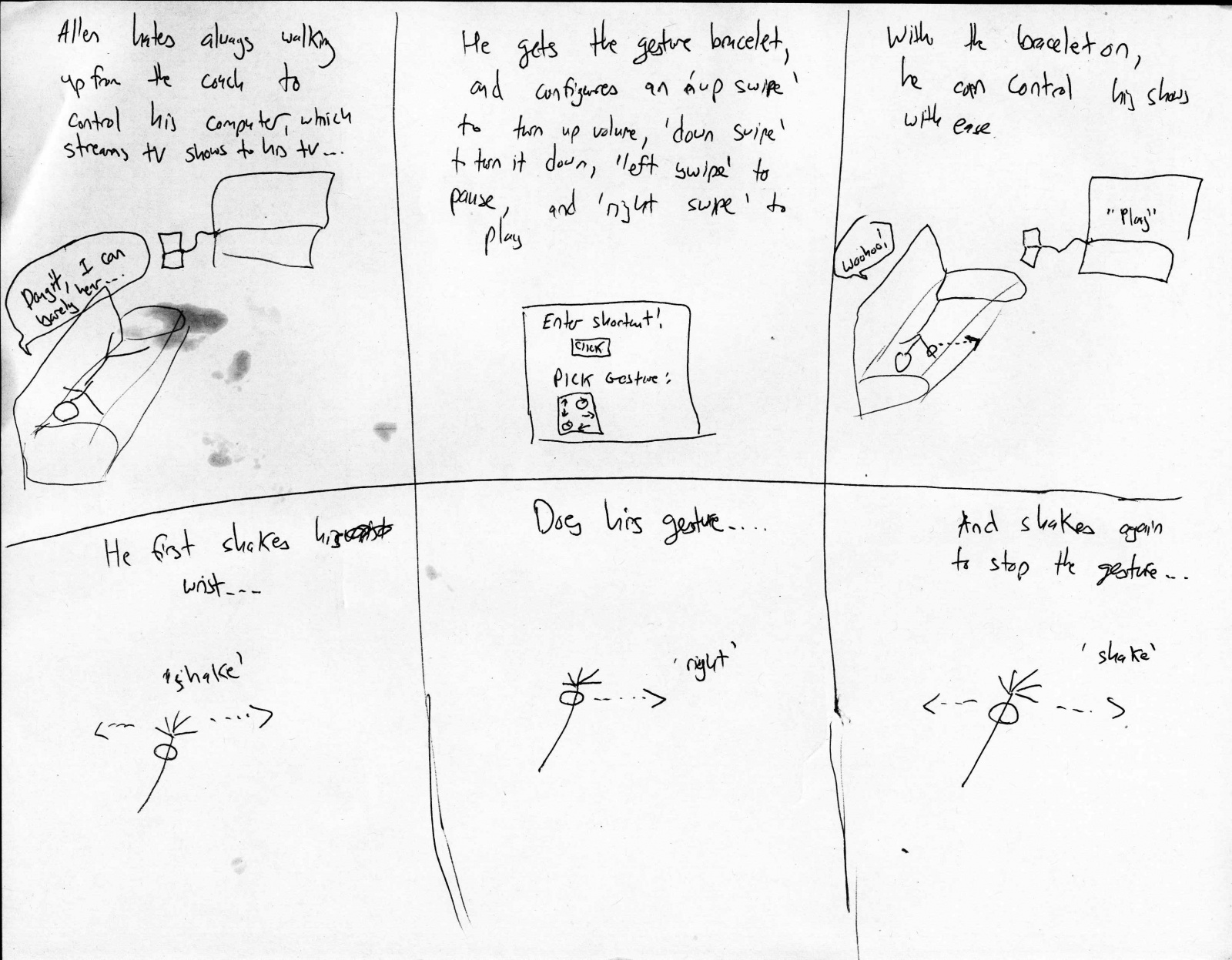
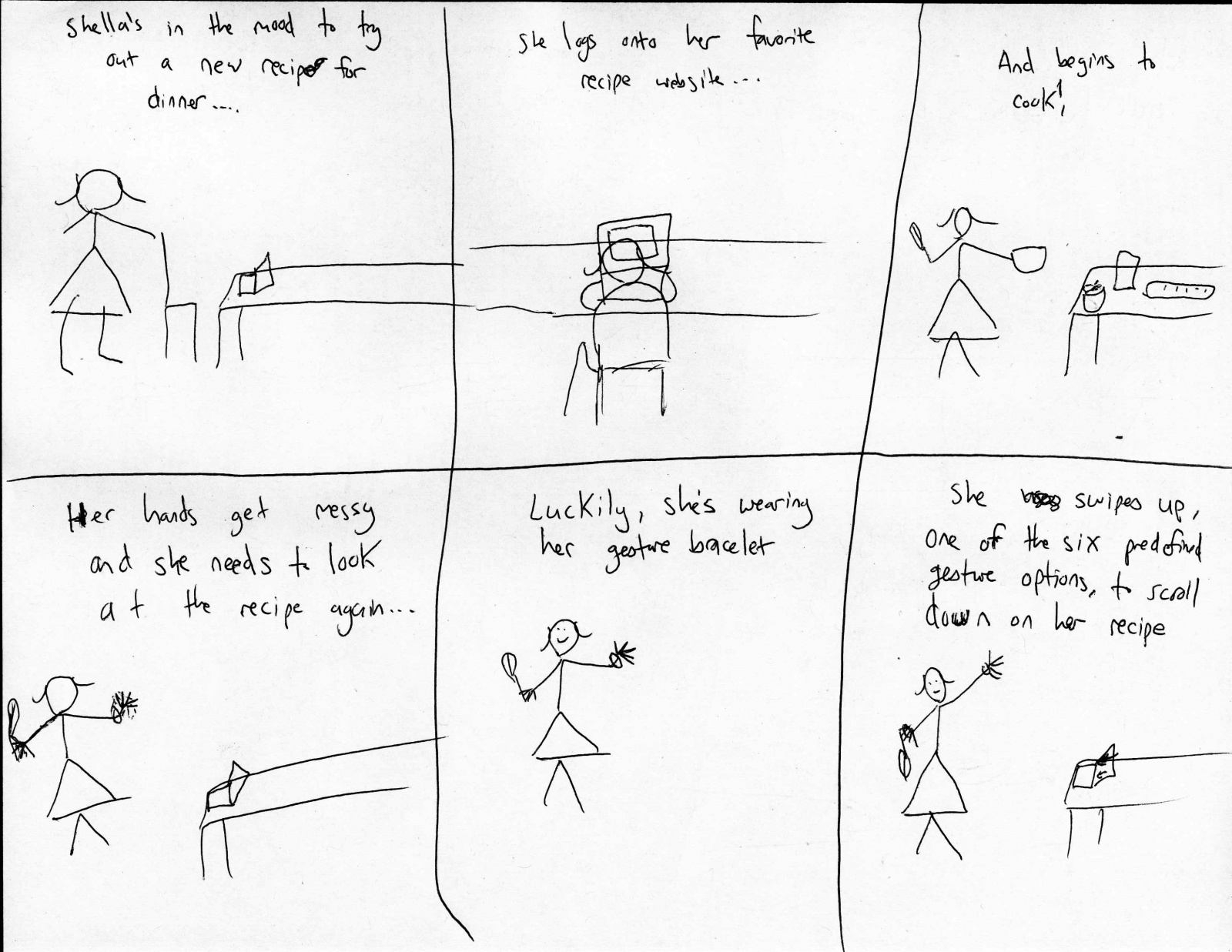
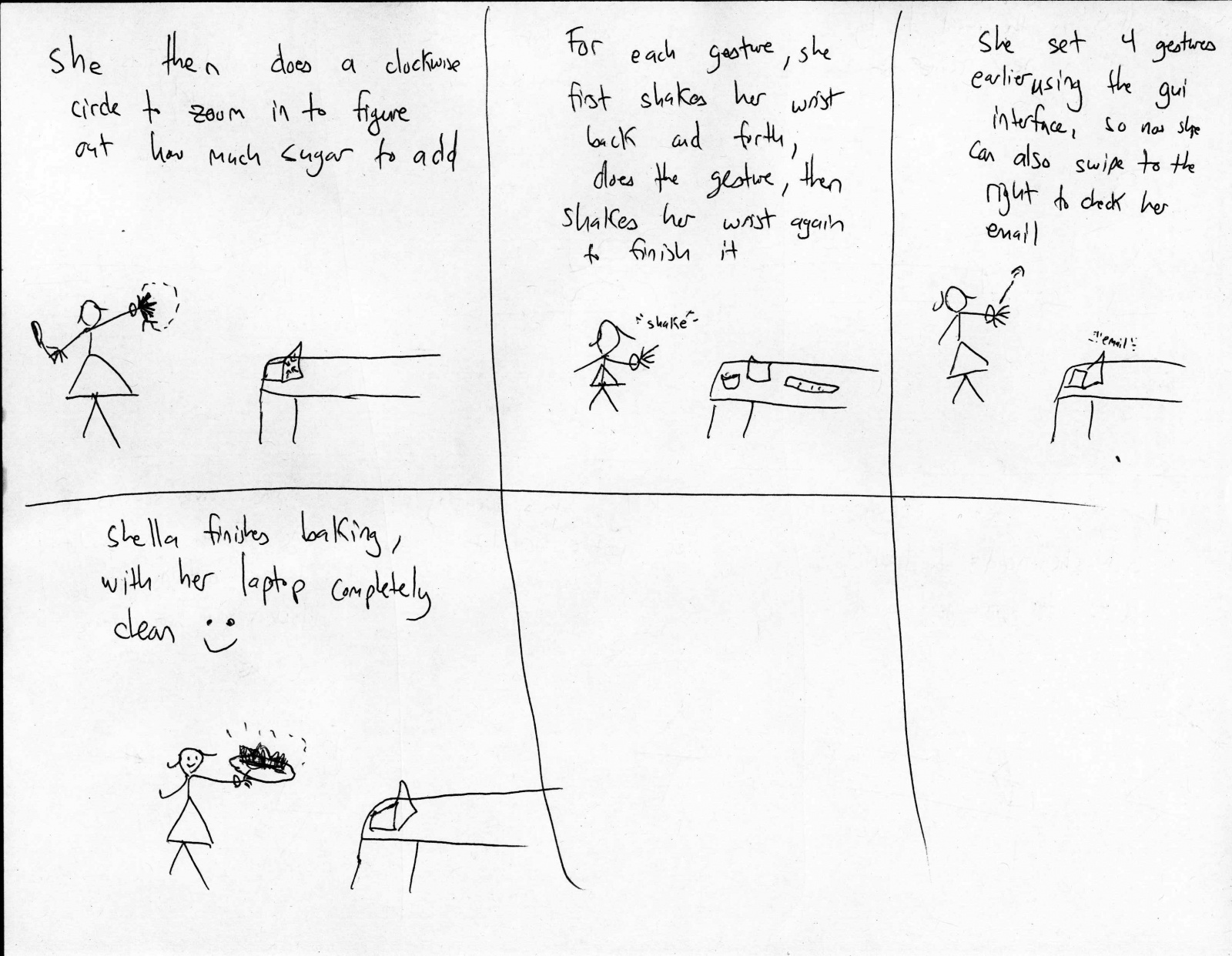
Below are the new storyboards that we picture for the three tasks implemented:
story board for picking up phone:




story board for playing music:




story board for unlocking phone:




New Prototype Description:
We decided to implement all three tasks on mockup apps made through Processing. The recognition of gestures results in transitions between screenshots, which represent what would happen on an actual phone. Controlling calls and the unlocking process on one’s phone requires jailbreaking of a phone and hacking into its native functionality. This is possible (as seen by the existence of iPhone applications such as CallController which uses the accelerometer to control calls) but potentially dangerous to the phone if incorrectly implemented. So for the sake of the being able to instead concentrate on the user-interface, as opposed to details of the demo app, we implemented the program for desktop.
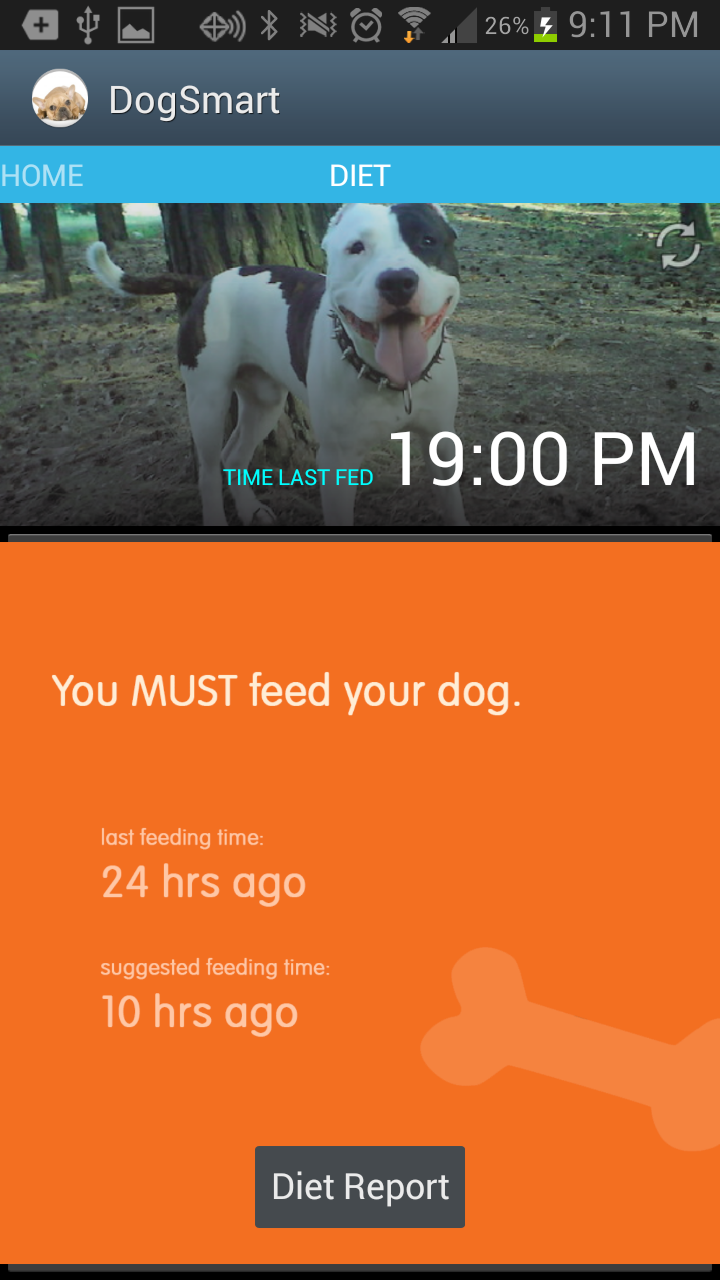
Using separate sketches in Processing, we implemented each of the three tasks described above. The phone call sketch has implemented functionality for answering and hanging up a call.
video of picking up a phone call:
The music playing sketch has implemented functionality for transitioning between songs, changing volume, pausing, and playing.
video of playing music:
The password setting and unlocking sketches have implemented functionality for setting a 3-gesture password, as well as method for recognition of the password.
video of setting a password:
video of unlocking phone:
The functionality that we did not implement in this prototype include the accelerometer and the voice command. The accelerometer was left out because it made the glove too clunky and was unnecessary, as explained above. The voice command was left out because, though it was useful, we found that it was one of the least complicated, and we would like to make sure that the more difficult tasks were possible as proof that our entire concept would work. In addition, with the voice command, the issue of user interface primarily falls on the voice recognition software in the phone, as opposed to our glove.
Each task in our prototype works without the aid of a wizard of oz. For now, to go to a different task, a wizard must run the right sketch in Processing. Though we have minimal human interference, our prototype is not a fully functional smartphone app. As stated above, neither Android nor iOS allow a 3rd party app to access functions like answering a call, probably because the app could break that feature if it is built incorrectly. However, we could still imagine the program being issued by the makers of the various smartphone OS’s as a built in tool, much like voice is currently.
Here is a link to all our code: https://www.dropbox.com/sh/b6mnt5mg4vafvag/yIBTTAcZ6t. We referenced Processing tutorials for making buttons: http://forum.processing.org/topic/simple-button-tutorial, as well as Processing tutorials for connecting to Arduino.